
The Verification Problem: Why Your AI Agent Gets the Right Answer But Picks the Wrong One
The gap between what LLMs can generate and what we actually use is the hidden failure mode of modern AI systems.

Your LLM is smarter than you think. The real problem isn’t generating good answers. It’s recognizing them.
Give Llama 70B 100 attempts at a hard math problem, and 98.6% of the time, at least one attempt is correct. But ask a reward model to pick the right one? It succeeds only 78% of the time. The space between what your model can produce and what you actually use is called the generation-verification gap. If you’re building agents, it’s probably your biggest silent failure mode right now.
I read four key research papers on this topic and distilled them into the findings that matter most for practitioners. Here’s what you need to know.
TLDR
Wanna hear an interactive version? Then check out this notebook LLM version!
Finding 1: Don’t Make Your Model Smarter — Make Your Picker Better
The most counterintuitive finding across this research is this: a cheap model with a good verifier often beats an expensive model with no verifier.
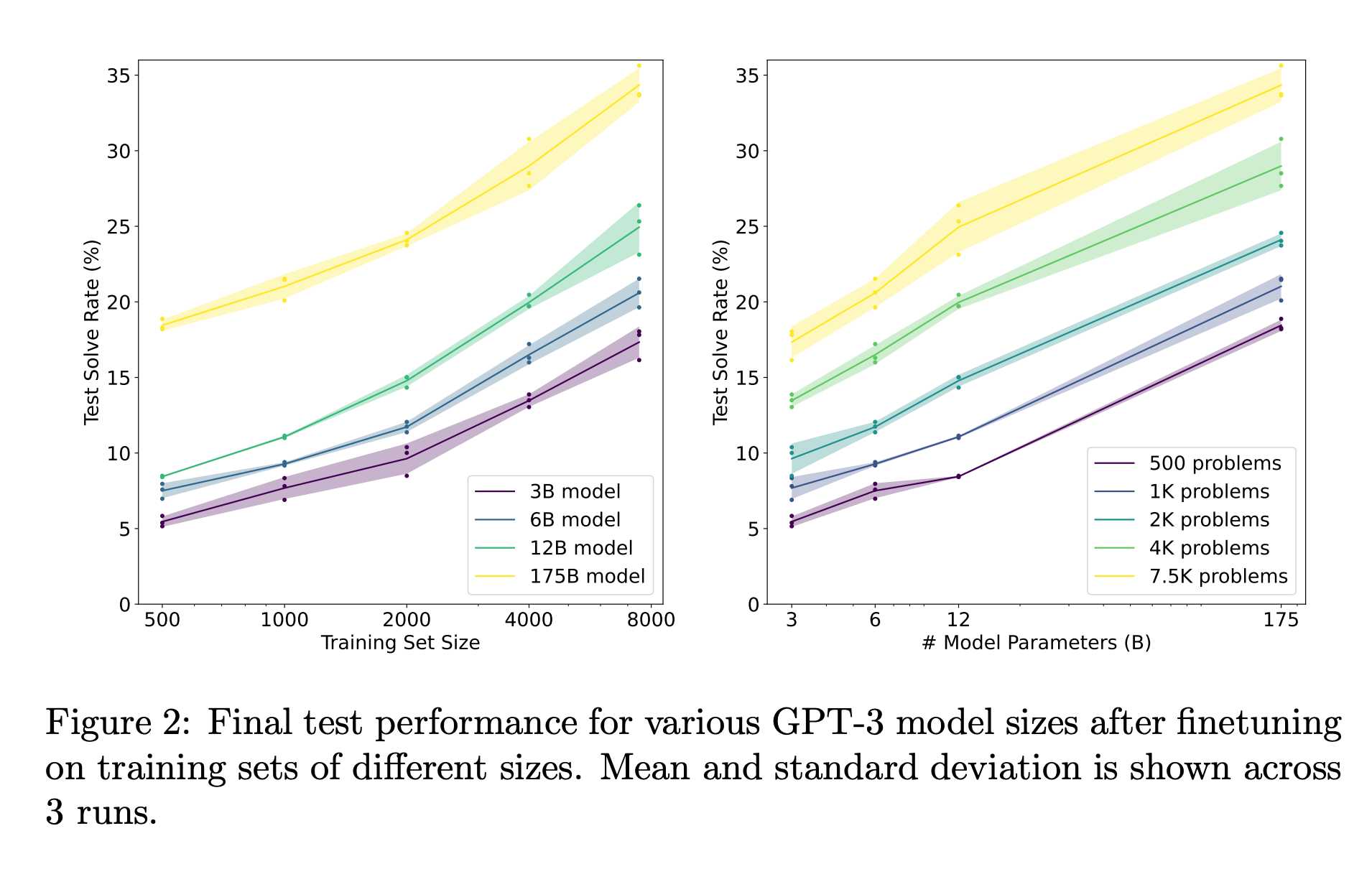
OpenAI showed this back in 2021. A 6B parameter model that generates 100 candidate answers and uses a verifier to pick the best one performs as well as a 175B model giving a single answer. That’s a 30× size reduction, just by adding a “judge” on top.
The intuition is simple. Generating a correct solution requires getting every step right. Checking whether a solution is correct is much easier. You just need to spot if something went wrong. Think of it like writing vs. proofreading. Proofreading is fundamentally easier.
What this means for agent builders: Before you upgrade to a bigger, more expensive model, try this first — have your current model generate 5-10 candidate responses and add a verifier to pick the best one. You’ll likely see bigger gains at lower cost.
Finding 2: Check Each Step, Not Just the Final Answer
There are two ways to verify an LLM’s output:
Outcome verification: Look at the final answer and ask “is this correct?”
Process verification: Look at each reasoning step and ask “is this step correct?”
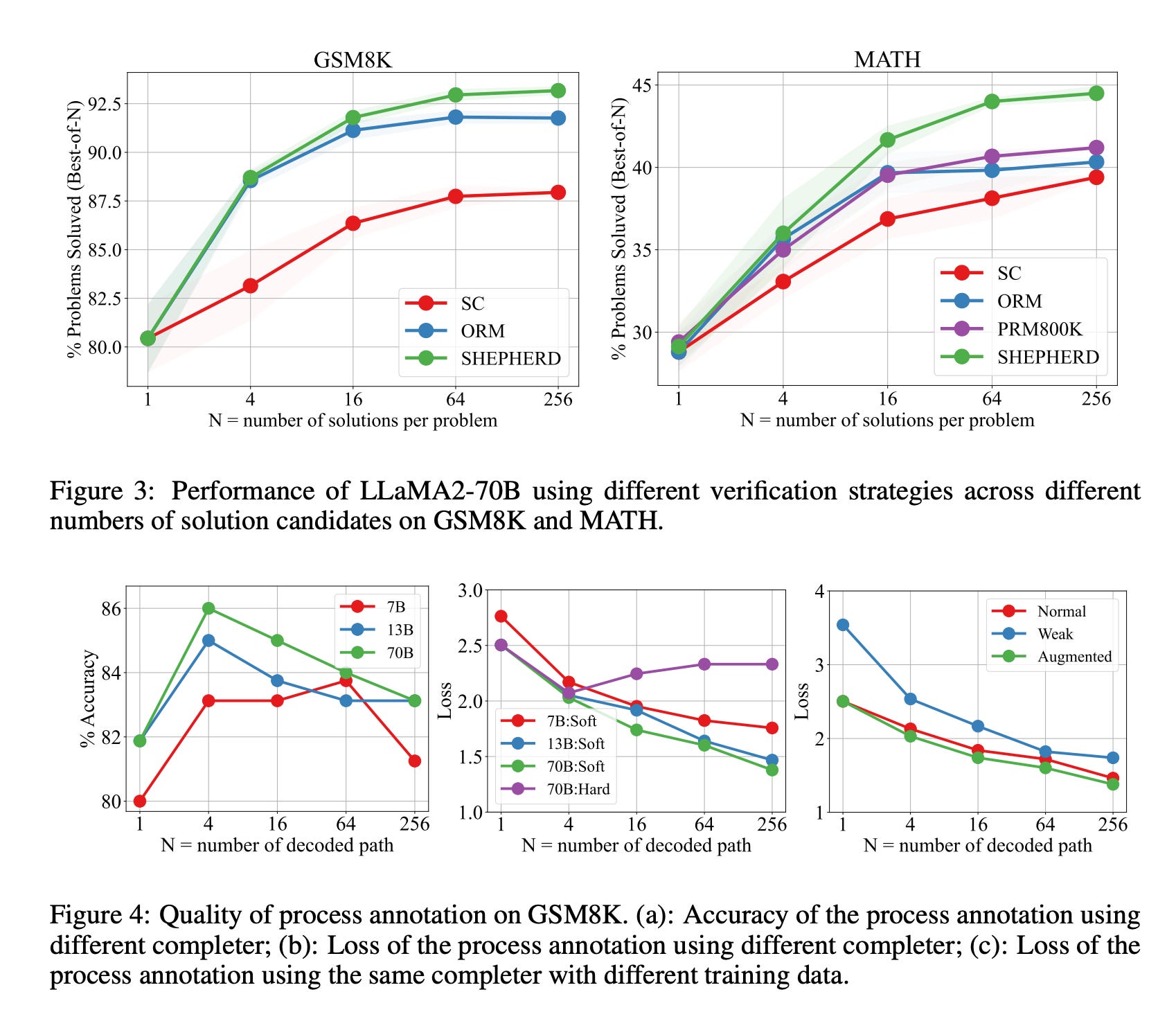
Process verification wins, and it’s not close. On challenging math problems, a process verifier solved 78.2% of problems, compared to 72.4% for an outcome verifier. More importantly, this gap grows wider as you give the model more attempts. The process verifier keeps improving with more candidates while the outcome verifier plateaus.
Why? It comes down to finding the mistake. If a 10-step solution reaches a wrong answer, an outcome verifier just knows “something went wrong.” A process verifier knows “Step 4 is where it broke.” That’s a much richer learning signal.
There’s a bonus: process verification is also safer. Outcome verifiers can learn to reward solutions that reach the right answer through wrong reasoning, basically rewarding lucky guesses. Process verifiers reward sound reasoning directly.
What this means for agent builders: If your agent does anything multi-step (research, then summarize, then answer, or plan, then code, then test) don’t just check the final output. Verify each intermediate step. This is especially critical as chains get longer, because the chance of a single step going wrong increases with every additional step.
Finding 3: You Can Build Step-Level Verifiers Without Human Labels
The obvious objection to step-level verification: who’s going to label every step of every solution as correct or incorrect? OpenAI’s PRM800K dataset required 800,000 human step-level labels. That’s expensive.
MATH-SHEPHERD solved this with a clever trick borrowed from game-playing AI called Monte Carlo Tree Search. The idea: a step is “good” if you can still reach the right answer from it.
Here’s how it works:
Take a solution and pause at Step 3
From Step 3, have an LLM try to complete the solution 8 different ways
If most completions reach the correct answer → Step 3 is probably good
If no completions reach the correct answer → Step 3 is probably bad
That’s it. No human annotators needed. And it works. This automatic method matches human annotation accuracy at 86%. The resulting verifier actually outperforms one trained on OpenAI’s expensive human-labeled dataset, partly because the automatic approach scales to 4× more training data.
What this means for agent builders: You can build a step-level verifier for your own domain today. The recipe is simple: (1) collect problems with known correct answers, (2) have your LLM generate step-by-step solutions, (3) for each step, run a few completions and measure how often they reach the right answer, (4) train a small model on these automatic labels. This works for anything where you can check the final output — code that must pass tests, queries that must return relevant results, plans that must satisfy constraints.
Finding 4: No Single Verifier Is Good Enough — But Combining Weak Ones Is
Here’s the uncomfortable truth: every individual verifier is unreliable. The best single reward model on standard benchmarks only gets 78.2% accuracy when picking answers. Even multi-agent verification (having LLMs judge each other) only gets to 71.6%.
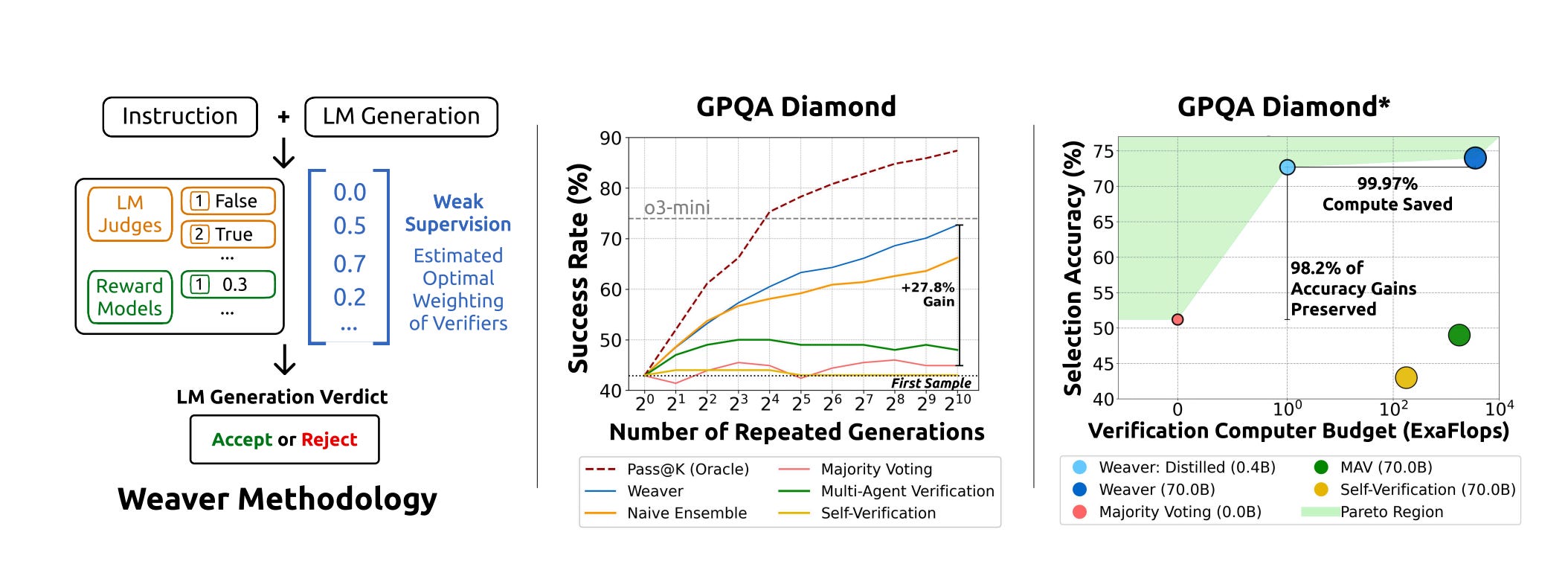
The breakthrough from the Weaver paper: combine many mediocre verifiers into one strong one. The researchers took 33 different open-source verifiers, a mix of reward models and LLM judge setups, and combined their scores with learned weights.
But the trick isn’t just averaging. Individual verifier accuracy varies wildly, by up to 37.5 percentage points. A simple average lets terrible verifiers drag down good ones. You need weighted averaging, where better verifiers get more say.
The clever part: Weaver figures out the weights without needing labeled data. It uses a statistical technique called weak supervision that estimates each verifier’s accuracy by looking at how often verifiers agree and disagree with each other. If Verifier A and Verifier B usually agree, and Verifier C often disagrees with both, the system can infer that C is probably less accurate, all without ever knowing the right answer.
The result? Llama 70B with Weaver scores 87.7% on average across hard benchmarks. OpenAI’s o3-mini (a model specifically trained for reasoning) scores 86.7%. A standard instruction-tuned model with good verification matched a frontier reasoning model, using only inference-time techniques.
What this means for agent builders: Don’t rely on a single LLM judge or a single reward model. Grab 5 to 10 diverse open-source models, have each one score your agent’s outputs, and combine their scores with higher weight on the more reliable ones. Diversity matters more than individual quality here. Use different model families and different verification approaches (some reward models, some prompted judges).

Finding 5: You Can Shrink Your Verifier 100× for Production
Running 33 verifiers per query is fine for research but absurd for production. Weaver’s solution: distill the ensemble into a single tiny model.
They trained a 400M parameter cross-encoder (based on ModernBERT) to mimic the ensemble’s combined scores. This tiny model:
Retains 98.2% of the full ensemble’s accuracy
Reduces compute by 99.97% (three orders of magnitude)
Runs on a single 32GB GPU instead of requiring multiple 8 GPU nodes
Adds only 0.57% additional inference cost on top of generation
The approach is straightforward. Run the full ensemble offline on a batch of query/response pairs to generate pseudo-labels, then train the small model to predict those labels. It’s classic knowledge distillation, applied to verification.
What this means for agent builders: The path to production is: (1) build your verifier ensemble offline, (2) score a large batch of your agent’s outputs with the full ensemble, (3) distill those scores into a compact model you can run alongside your agent in real-time. You get ensemble-quality verification at single-model cost.
Finding 6: Verification Makes Small Models Punch Above Their Weight
One of the most practical findings: good verification lets small models compete with large ones.
An 8B model with Weaver verification comes within 1.6% of a 70B model using majority voting. A 70B model with Weaver surpasses o3-mini by 1.0%. MATH-SHEPHERD showed that Mistral 7B with step-level reinforcement learning and verification reaches 89.1% on GSM8K.
But there’s an important asymmetry: your verifier should be at least as strong as your generator. When researchers paired a small verifier with a large generator, verification actually hurt performance. But a large verifier with a small generator gave massive gains. The verifier needs to be sophisticated enough to evaluate what the generator produces.
What this means for agent builders: If you’re cost-constrained, consider running a smaller generator (which you call many times) paired with a stronger verifier (which you call once per candidate). This often gives better quality-per-dollar than putting all your budget into a single call to the biggest model available.
The Practical Takeaway
If you’re building agents or LLM-powered products, here’s the 30-second summary:
Sample multiple outputs and pick the best one. This alone can give you the equivalent of a 30× larger model.
Verify each step, not just the final answer. Multi-step agents benefit enormously from intermediate checkpoints.
You don’t need human labels to train verifiers. Monte Carlo completion lets you build step-level verifiers automatically for any domain with checkable outputs.
Combine multiple cheap verifiers instead of relying on one expensive one. A weighted ensemble of open-source models can match frontier reasoning models.
Distill for production. A 400M model can carry 98% of an ensemble’s signal at 0.03% of the cost.
The generation-verification gap is probably the single biggest source of wasted capability in your current system. Closing it doesn’t require a better model. It requires a better picker.