
Test-Time Compute Scaling: A Practical Guide for LLM & Agentic System Builders
The era of "just train a bigger model" is ending. The new scaling frontier is inference time.

Test time compute is replacing “train a bigger model” as the main way to improve LLMs. Models like o1, o3 and DeepSeek R1 win by letting the model think longer at inference, not just by adding parameters.
Most teams respond by increasing sampling and turning on chain of thought, which is expensive and only partly effective. This post distills four recent papers on test time scaling into a simple mental model, a few key results about how performance really scales, and concrete defaults for when to spend FLOPs on pretraining versus inference.
TLDR
Wanna hear the short Notebook LLM interactive version instead? Play it here now!
Mental Model: Proposer + Verifier
A simple way to design test time compute is to separate proposing from checking.
The proposer is everything that generates candidates. One greedy answer, four chains of thought, three self revisions of a draft, ten candidate tool plans: these are all different proposers. In code, this is your generate() or sample_candidates() call and any revision loop you wrap around it.
The verifier is everything that decides which candidates survive. It can be as simple as picking the highest log probability answer, or as rich as running unit tests on code, checking numeric consistency in math, or using a small model to rank and score responses. For agents, tool feedback is also a verifier: database errors, API status codes, and unexpected result shapes are all signals that a candidate path is bad.
Once you see this split, you can make concrete choices.
For a math or coding agent, let the proposer generate several solutions, then let the verifier run tests and keep the first one that passes. If this is too slow, keep the number of samples fixed and make the verifier smarter, for example by adding simple static checks so obviously broken candidates are rejected before you run heavy tests.
For an instruction following assistant, you often get more value from a stronger proposer than from a very strict verifier. A practical pattern is: answer once, ask the model to critique that answer, then produce a revised answer. A small ranking model or even a heuristic score can then choose between original and revised.
For a multi tool agent, treat each tool call as verification. The proposer suggests a plan and actions, the verifier is the environment: tools either succeed or fail, and you use that signal to revise the plan on the next step.
To make this actionable in your own system, ask three questions for each use case:
How many candidates can I afford to propose before latency or cost becomes a problem
What cheap checks do I already have that could act as verifiers, such as tests, type checks, constraints, or smaller ranking models
Given my FLOPs budget, is it more useful here to add diversity in proposals, add revision steps to one proposal, or improve the checker
Answering those in concrete terms for your stack gives you a far better design than simply turning up sampling and hoping for the best.
Key Result #1: Difficulty-Dependent Strategies
A core result from the test time compute work is very simple: the right strategy depends on how hard the prompt is for your base model.
On easy prompts, the model already “knows what to do.” A single chain of thought plus one or two self revisions is usually the best use of extra compute. For agents, this suggests a cheap mode where you let the model think a bit longer on one trajectory, then act.
On medium prompts, the first attempt is often half right. Here you get more value from a mix of exploration and refinement: generate a few candidates, allow one revision step on each, then pick using a checker. For agents, this can be the default for “important but not critical” tasks: small pool of plans, one round of improvement, then select.
On hard prompts, revising one idea usually does not help, because the high level plan is wrong. You only see gains when you explore qualitatively different strategies in parallel and guide them with a stronger verifier, such as a process reward model or strict tool based checks. For agents, this is the “escalation path” for genuinely difficult queries: more branches, stronger checking, and a tighter budget cap.
If nothing improves even when you do all three, the problem is outside your model’s capability. In that case, the right move is not more test time compute, but a better base model or different data.
Key Result #2: Why Sampling Looks Like a Power Law
When you increase the number of samples, accuracy often seems to improve in a smooth power law curve. It looks like “each extra sample helps a bit.”
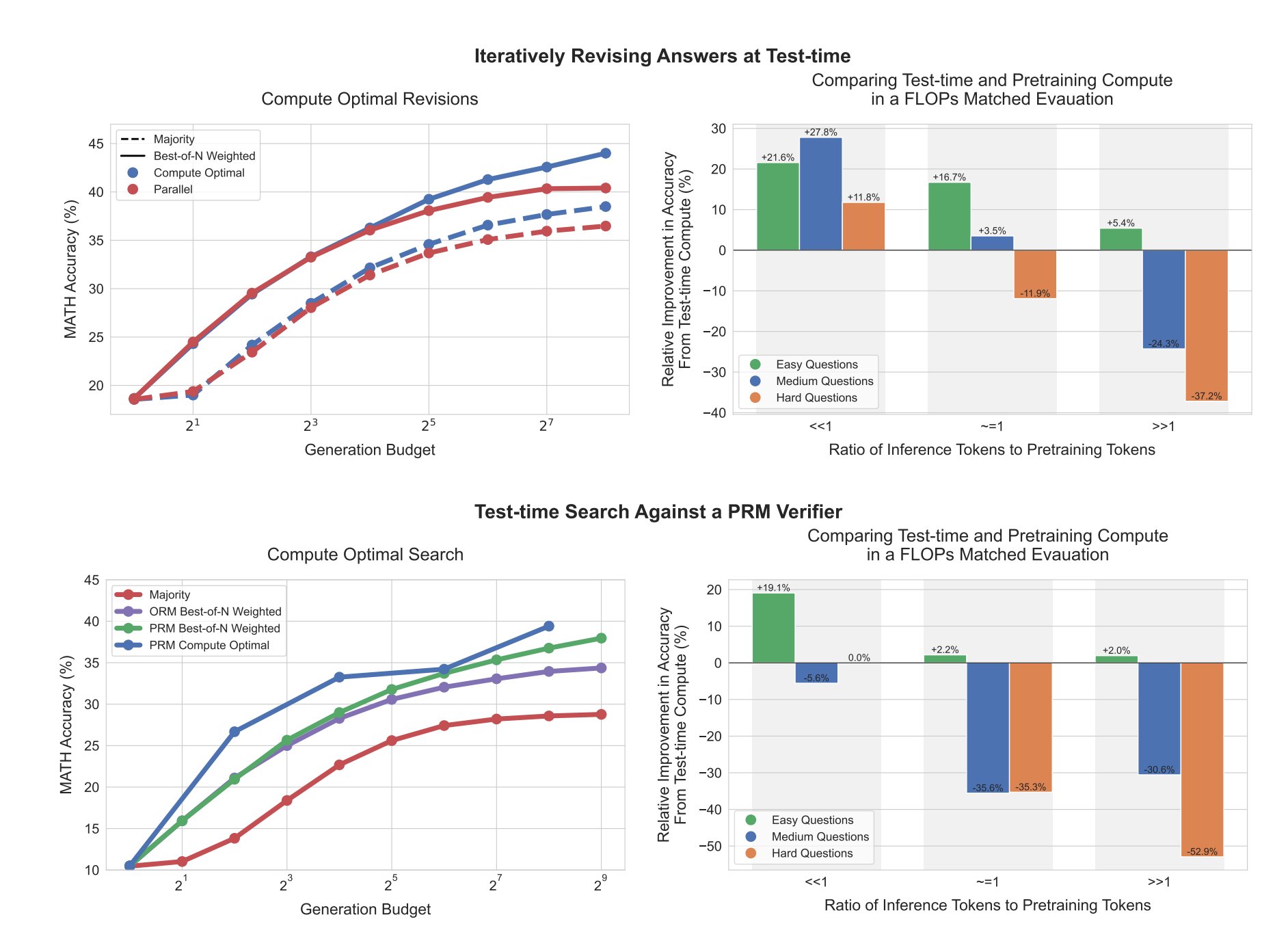
What actually happens is more lopsided.
For any single question, extra samples help very quickly at first. If the model has a reasonable chance of being right on one try, then a few independent tries are usually enough to get it right at least once. Per question, the value of sampling drops off fast.
The power law shape only appears when you average over many questions. Most are either easy and get solved with one or two samples, or extremely hard and almost never get solved. A small tail of hard questions, which need many attempts before they succeed, is what bends the overall curve into a smooth trend.
For people building agents, the takeaway is simple. Extra sampling mainly helps that hard tail of questions. It does not give proportional gains on every request.
Key Result #3: Architectures Beat Ad Hoc Pipelines
A key finding from the architecture work is that a simple, explicit structure beats a pile of loosely connected tricks.
In many setups today, people bolt things on over time: first chain of thought, then best of N, then a reranker, then a verifier. The result often works, but no one can say which part is actually doing the heavy lifting, and it is hard to improve systematically.
The alternative is to treat inference as a small architecture built from standard blocks. You have generators that produce candidates, critics that point out issues, rankers that sort options, fusers that merge or rewrite, and verifiers or tests that check correctness. An actual system might look like “several generators, then a critic, then a ranker, then a fuser, then a verifier,” rather than an unstructured chain of if statements.
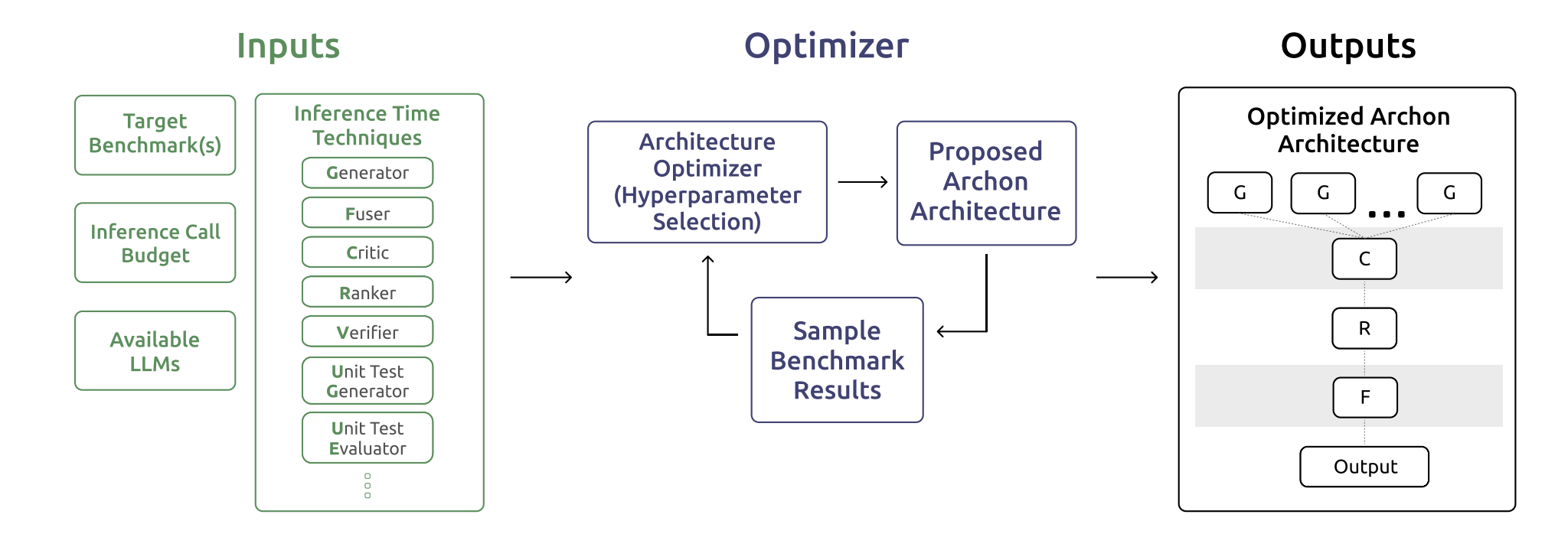
Empirically, such layered architectures perform better than using any single technique alone, even at similar compute. They also give you clear knobs to tune: how many generators, how many critique or fusion steps, where to place verification.
For people building agents, the practical move is to write down the blocks you already use and fix an explicit order for them, instead of adding features in whatever place is most convenient. Once you have that architecture, you can iterate on it like any other model component, rather than debugging a growing collection of special cases.
Practitioners’ Playbook
For agents, it helps to fix a small set of default modes and be strict about when you use each.
First, add a simple difficulty signal. For example, log whether the first attempt for a given task type usually works, sometimes works, or almost never works. You can also use cheap signals like how often similar tasks have failed, or a basic verifier score on the first answer.
Then wire three behaviors:
Easy tasks
One chain of thought, one quick self-check or revision, then act.
Use this for queries where the first attempt is almost always fine.Medium tasks
Generate a small number of candidate plans, let the model refine each once, then pick with a simple checker, such as unit tests, tool feedback, or a lightweight ranking model.
Use this where the first attempt is hit or miss.Hard tasks
Allow more branches and stricter checking. Multiple plans in parallel, aggressive use of tools and tests, and a clear limit on total steps or samples.
Use this only when the difficulty signal says the task is genuinely hard or important.
Make these modes explicit in your code, for example by passing a “reasoning level” or “compute tier” into your agent. Start everyone in cheap mode, upgrade to medium or hard only when the difficulty signal says it is worth it, and log how often the upgrade actually changes the final outcome. If a heavy mode rarely changes the answer for a task slice, turn it off there.