
Data Science Interview Guide – Part 5: Random Forests

If you have ever trained a decision tree and noticed that it performs very well on the training data but poorly on unseen data, you have already encountered the core weakness of trees: overfitting.
Decision trees are intuitive and easy to interpret, but they tend to capture noise and make unstable predictions when the input data changes slightly. Random Forests were designed to solve this problem.
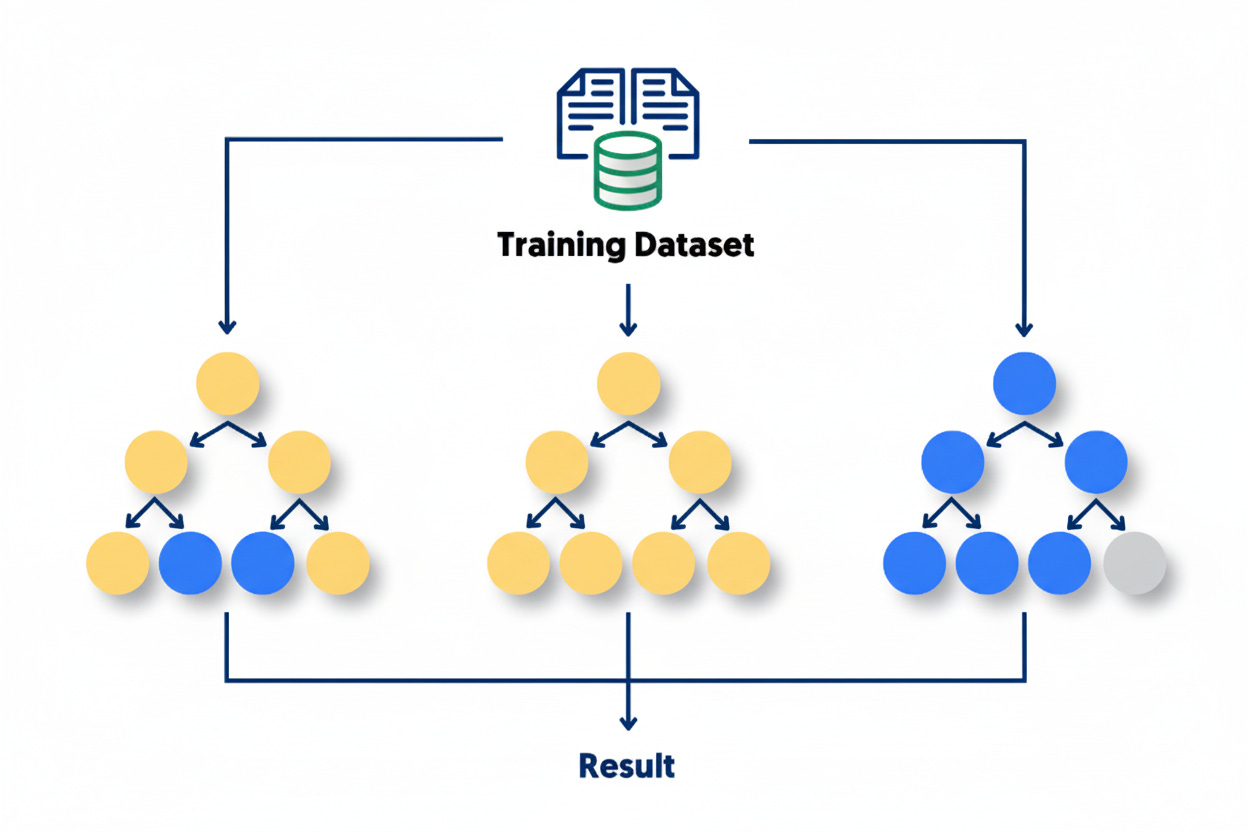
The main idea is simple: instead of relying on a single decision tree, build many of them, each slightly different, and let them collectively make the final decision. This ensemble of trees forms a “forest,” and by averaging or voting across multiple trees, the model becomes more accurate and more stable.
Random Forests combine the interpretability of decision trees with the power of ensemble learning. They are versatile, robust, and perform well with minimal tuning. In practice, they are widely used for both classification and regression tasks in areas such as credit scoring, fraud detection, medical diagnosis, and recommendation systems.
In this post, we will explore how Random Forests work, why they perform so well, how to optimize them for better results, and what key concepts are most commonly tested in machine learning interviews.
The Core Idea: Ensemble Learning and Bagging
Before we can understand how Random Forests work, we first need to look at a broader concept called ensemble learning. The idea behind ensemble learning is simple but powerful: rather than depending on one model to make predictions, we combine several models and use their collective judgment. Just like a group of people can make a better decision together than one person alone, a group of models can produce more accurate and stable predictions.
Every model we train has some level of error. Part of that error comes from the limitations of the model itself, and part comes from the randomness in the training data. If we train multiple models that make slightly different mistakes, combining them can help those errors cancel each other out. This is the central idea behind ensemble learning — using diversity among models to improve overall performance.
One of the most common ensemble techniques is bagging, which stands for bootstrap aggregation.
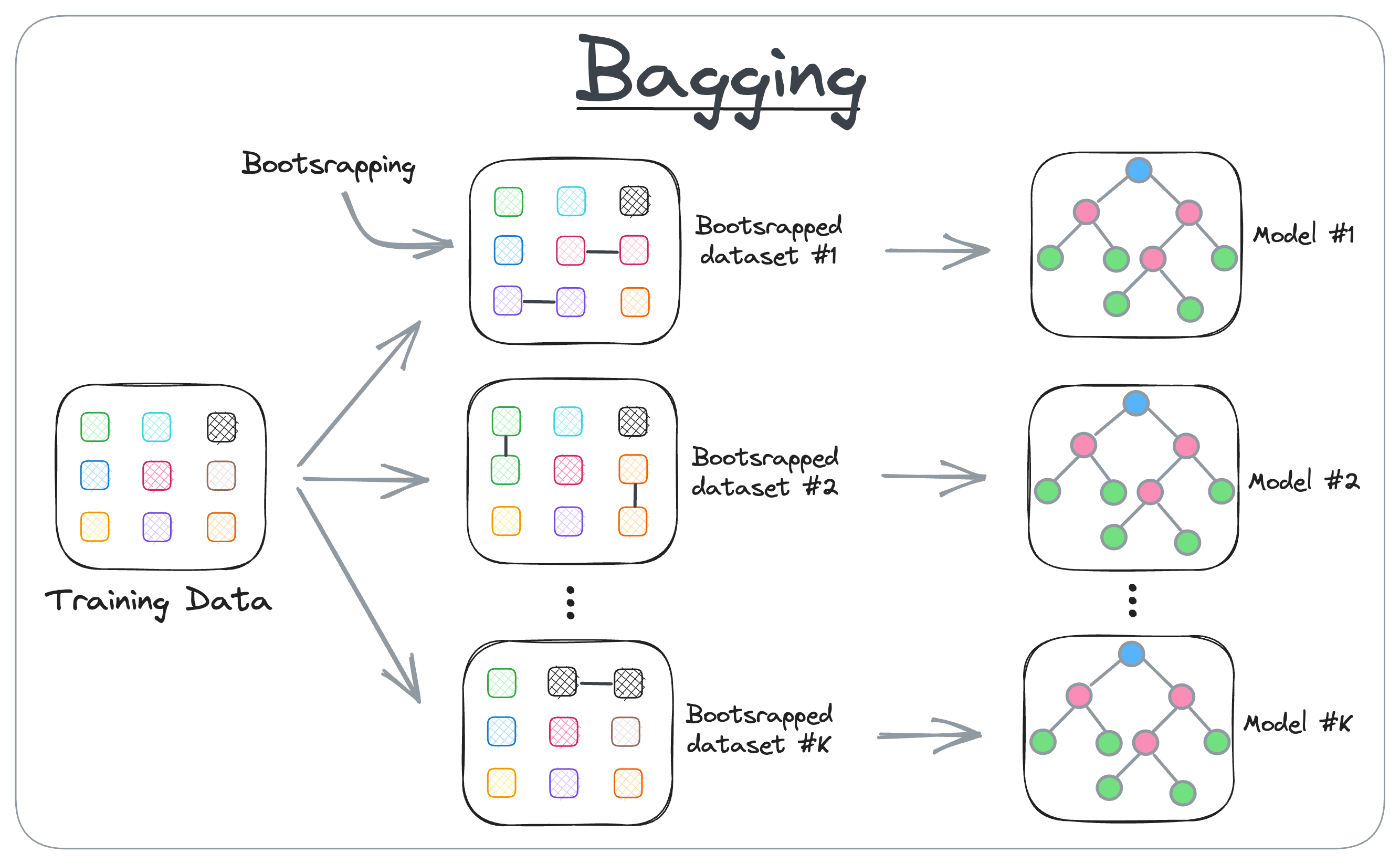
Bagging combines the ideas of random sampling and averaging predictions. Here’s how it works: we take our original training data and create several new datasets by randomly sampling data points with replacement. This means that some examples might appear more than once in a sample, while others might not appear at all. Each of these datasets is then used to train its own model, usually of the same type, such as a decision tree. Once all models are trained, their predictions are combined to make a final decision.
For classification problems, the models vote, and the class that gets the majority of votes becomes the final prediction. For regression problems, we simply take the average of all predictions. The idea is that by combining many “noisy” models, the noise averages out, and what remains is a stronger, more reliable prediction.
The main advantage of bagging is that it helps reduce variance. Models like decision trees are very sensitive to the data they are trained on — small changes in the training set can lead to very different trees. This makes them unstable. Bagging reduces this instability by averaging the results of many different trees trained on slightly different data. The result is a smoother, more consistent model that performs better on unseen data.
An interesting outcome of the bagging process is the concept of out-of-bag (OOB) samples. Because each bootstrap sample leaves out some data points, about one-third of the original training data is not used for training a particular model. These unused data points can then serve as a built-in validation set to test how that model performs. By using out-of-bag samples across all models, we can estimate how well the overall ensemble is performing without the need for a separate validation set.
Bagging tends to work best with models that are naturally unstable, meaning their predictions change a lot when trained on slightly different data. Decision trees are a classic example, which is why bagging them works so well. Stable models, like linear regression, do not benefit much because their predictions barely change between samples. So, bagging is particularly useful when you start with a high-variance model that you want to make more stable.
In essence, bagging improves the reliability and accuracy of machine learning models by combining many versions of them, each trained on a random slice of the data. It helps prevent overfitting, increases robustness, and provides a simple way to estimate performance through out-of-bag validation. This technique is the foundation upon which Random Forests are built. In the next section, we will see how Random Forests take the idea of bagging one step further by adding an extra layer of randomness to make the ensemble even more powerful.
Random Forest: A Smarter Ensemble of Trees
Now that we understand the idea of ensemble learning and bagging, we can look at how Random Forests build on that foundation. A Random Forest is essentially an improved version of bagged decision trees. It uses the same idea of combining multiple trees trained on different subsets of data, but it adds one more important twist - it introduces randomness not only in the data but also in the selection of features.
Let’s start from what we already know. In bagging, every tree in the ensemble is trained on a different random sample of the dataset. However, when each tree decides where to split, it considers all available features to find the best one. This can cause a problem. If some features are much stronger predictors than others, every tree will tend to pick those same features near the top of the tree. As a result, the trees will end up looking very similar to each other. When trees are too similar, their predictions become highly correlated i.e. they will make the same type of errors - which means the averaging process does not reduce variance as much as it could.
Random Forest solves this problem by introducing feature randomness. When a tree in the forest tries to split a node, it does not consider all features. Instead, it looks at a random subset of features and chooses the best split only from those. This small change makes a big difference. It forces each tree to explore different parts of the feature space, leading to more variety among the trees. The greater the diversity among trees, the more different the type of errors, the more effective the averaging becomes at reducing variance, and the stronger the overall model performs.
Here’s how the Random Forest process works step by step:
Take a random sample of the data (using bootstrapping).
Train a decision tree on this sample.
At each split in the tree, select a random subset of features and determine the best split only among them (how are splits made? Check our blog on decision trees for a deep dive on this)
Repeat the process to grow many trees, each trained on a different random sample and using different feature subsets.
When making predictions, aggregate the results of all trees — by majority vote for classification or by averaging for regression.
This approach creates a collection of trees that are individually imperfect but collectively powerful. Each tree might overfit its small sample of data, but when hundreds of trees are averaged, the overfitting largely disappears. The result is a model that maintains low bias (because trees are deep and flexible) but achieves low variance (because their predictions are averaged). This balance is what makes Random Forests so effective in practice.
Another advantage of Random Forests is that they are robust. They work well even with default hyperparameters. You rarely need to fine-tune them heavily to get good results. They can handle both numerical and categorical features, manage missing values reasonably well, and are resistant to overfitting on noisy data. This is one reason why Random Forests are often used as a strong baseline in many machine learning projects.
In summary, Random Forests take the idea of bagging and make it smarter. By adding randomness to both the data and the feature selection process, they create an ensemble of diverse trees whose combined predictions are more accurate and stable than any single tree alone.
What is Out-of-Bag Samples and Error?
One of the most useful features of Random Forests is that they can estimate their own performance without the need for a separate validation set. This is made possible by something called out-of-bag (OOB) samples. The concept comes directly from the way Random Forests are trained using bootstrap sampling.
When each tree is built, it is trained on a random sample of the original dataset. Because this sampling is done with replacement, some data points appear more than once in a sample, while others are left out entirely. On average, about two-thirds of the original data points are included in each bootstrap sample, and the remaining one-third are left out. These left-out data points are called out-of-bag samples.
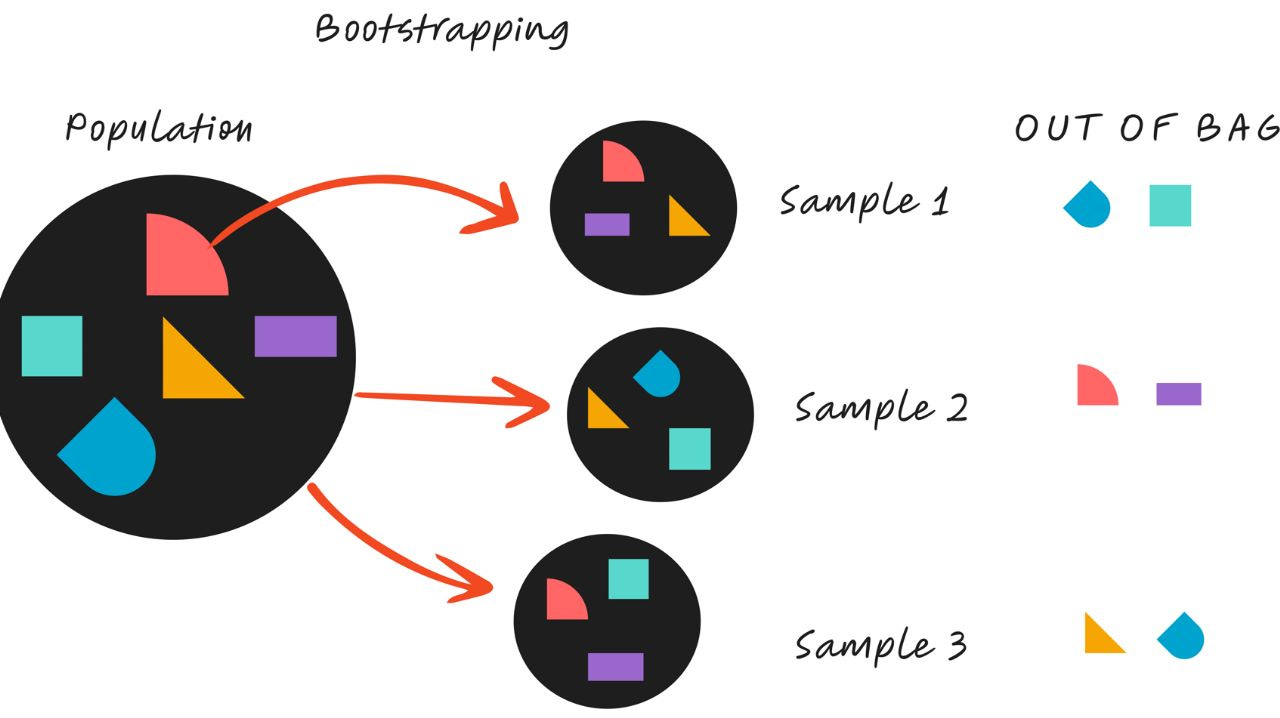
The key idea is that each tree can be tested on the data it did not see during training. Since every data point is left out of some trees’ training samples, we can use those trees to make predictions for that data point and see how accurate they are. When we repeat this process for all samples, we can calculate an overall performance metric such as accuracy (for classification) or mean squared error (for regression). This measure is known as the out-of-bag error.
Out-of-bag evaluation has a few major advantages:
No need for a separate validation set. The model effectively tests itself using the data it has not seen.
Efficient use of data. Because the entire dataset contributes both to training and to evaluation (across different trees), we make the most of limited data.
Fast performance estimation. Computing the OOB error adds almost no extra cost since it reuses the same samples already generated during training.
In practice, enabling out-of-bag scoring in libraries like scikit-learn is as simple as setting the parameter oob_score=True when creating your Random Forest model. The model will then report the OOB score after training, giving you a quick and unbiased estimate of how well it generalizes.
It’s worth noting that while OOB error estimates are typically close to the accuracy you would get from cross-validation, they can sometimes differ slightly, especially if your dataset is small or highly imbalanced. Still, for most practical purposes, the OOB score provides a reliable first look at model performance without the extra cost of setting up cross-validation.
Key Hyperparameters and Their Roles
Like most machine learning models, Random Forests have a set of hyperparameters that control how the model learns and how complex it becomes. The good news is that Random Forests usually work well with their default settings, but understanding what each parameter does can help you fine-tune the model for better performance and answer interview questions with confidence.
At a high level, Random Forest hyperparameters fall into two main groups:
Parameters that control the size and shape of individual trees, and
Parameters that control the overall behavior of the forest.
Let’s go through the most important ones.
n_estimators
This parameter sets the number of trees in the forest. More trees generally lead to better performance because averaging over more trees reduces variance. However, after a certain point, adding more trees gives diminishing returns and increases computation time. In practice, values between 100 and 500 are common starting points. You can increase this number until the model’s performance (or out-of-bag score) stops improving.
max_depth
This controls how deep each decision tree can grow. Deeper trees can capture more complex patterns but are also more likely to overfit. Setting a maximum depth limits that complexity. If you don’t specify a value, trees will keep splitting until all leaves are pure or until they contain too few samples to split further. In interviews, you can mention that controlling max_depth is one of the simplest ways to prevent overfitting.
min_samples_split and min_samples_leaf
These parameters control how many data points are required to make a split (min_samples_split) or to remain in a leaf node (min_samples_leaf).
Increasing min_samples_split means that a node must contain more samples before it can be divided, which results in fewer splits and simpler trees.
Increasing min_samples_leaf ensures that leaves have a minimum number of samples, which can smooth predictions, especially for regression problems.
Both parameters are useful for making trees less sensitive to noise in the data.
max_features
This parameter defines how many features the model should consider when looking for the best split at each node.
For classification tasks, a common default is the square root of the total number of features.
For regression tasks, the default is often one-third of the total number of features.
Choosing fewer features increases diversity among trees, which helps reduce correlation and variance. However, if you choose too few, the model might miss important splits and lose accuracy. This parameter is one of the most influential in balancing bias and variance in Random Forests.
If you need to take your interview preparation up a notch, join our live classes.
This gives you a chance to learn from Industry Data Scientists, ask questions, and understand how best to answer questions for even FAANG-level companies.
Seats are limited for these sessions, so sign up today!

bootstrap
This controls whether sampling is done with replacement when building each tree. If set to True (which is the default), each tree is trained on a random sample of the data, possibly containing duplicates. If set to False, each tree sees the entire dataset, which removes one source of randomness. In practice, leaving bootstrap=True usually leads to better generalization.
oob_score
When bootstrap sampling is enabled, about one-third of the data is not used for training each tree. These are the out-of-bag samples. If you set oob_score=True, the model will use those samples to estimate prediction accuracy internally, without needing a separate validation set. This is a convenient way to evaluate performance efficiently.
random_state
This parameter is not about model structure but about reproducibility. By fixing the random seed (using an integer value), you ensure that your Random Forest will produce the same results every time you train it on the same data. This is especially useful for debugging, testing, and explaining your results.
n_jobs
This parameter tells the model how many CPU cores to use for training. Setting n_jobs=-1 uses all available cores, which can significantly speed up training when building many trees.
Each of these hyperparameters influences the balance between bias, variance, and computation. In practice, you can often start with defaults and then tune a few key parameters, typically n_estimators, max_depth, and max_features, based on validation/OOB performance.
In interviews, be prepared to explain not only what these parameters do, but also how changing them affects the model. For example, increasing n_estimators reduces variance, while limiting max_depth reduces overfitting but increases bias. Understanding these trade-offs shows that you can reason about model behavior rather than just use it as a black box.
Hyperparameter Tuning
Once you understand what each Random Forest parameter does, the next step is figuring out how to find the best combination of them for your specific problem. Random Forests usually work well with their default settings, but careful tuning can make a good model noticeably better. The goal of tuning is not to chase perfection but to improve generalization without wasting time on unnecessary experimentation.
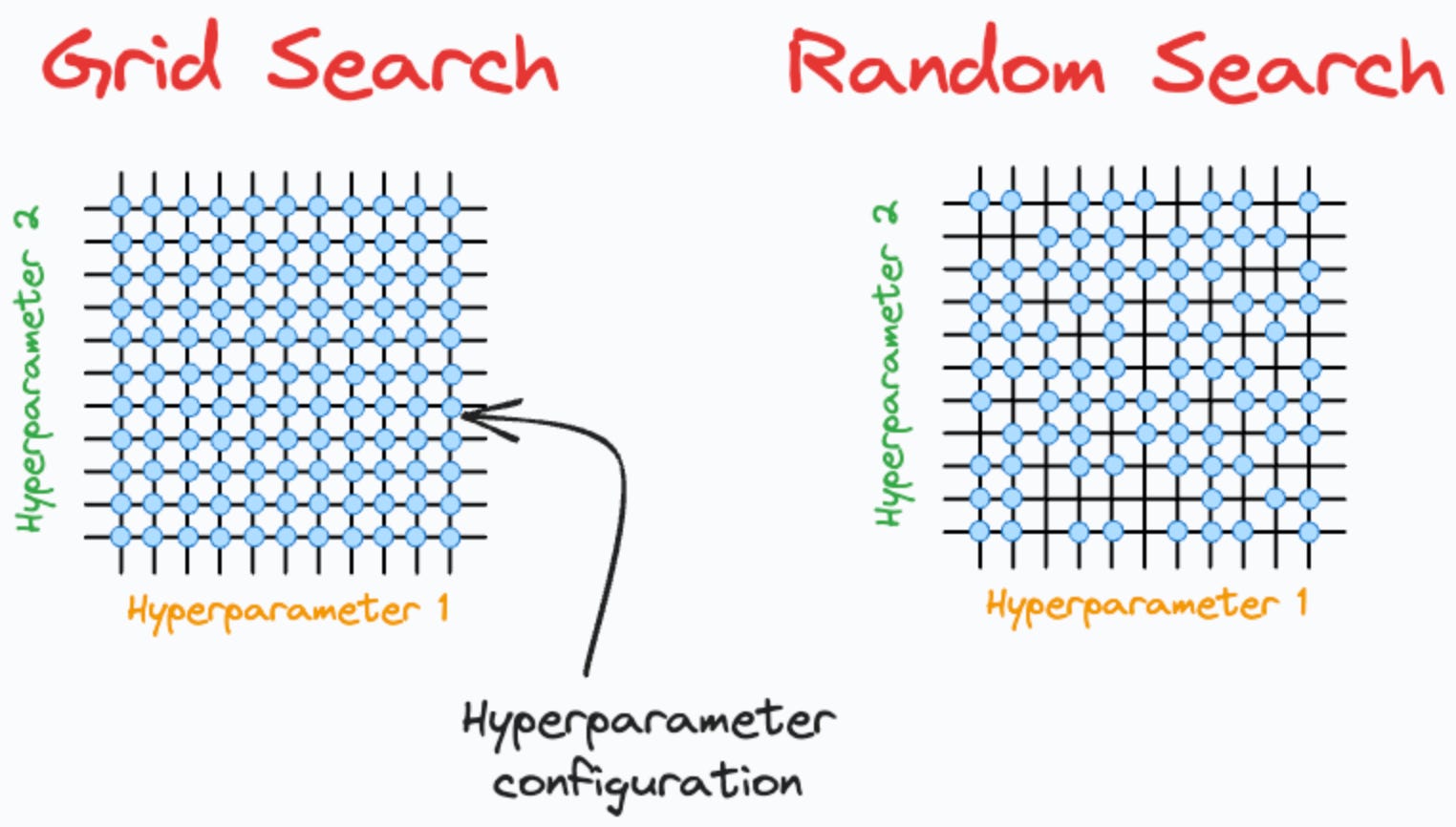
The most straightforward approach is Grid Search, where you define a few possible values for each parameter and test all possible combinations. This method is easy to understand and ensures you explore every option in the defined grid, but it becomes expensive when there are many parameters or when each one has several candidate values. Grid Search works best when you already have a sense of which ranges are reasonable, such as trying tree depths of 5, 10, and 15, or comparing 100, 300, and 500 trees.
If you are working with a larger search space, Random Search is often more efficient. Instead of testing every combination, it randomly samples from the parameter space for a fixed number of iterations. Studies have shown that Random Search can find near-optimal results much faster than Grid Search because not all parameters are equally important. For example, changing the number of trees may matter less than tuning the maximum depth or number of features. Random Search helps you discover good configurations early without testing every possibility.
For more advanced optimization, you can use Bayesian Optimization tools such as Optuna, Hyperopt, or Scikit-Optimize. These algorithms build a probabilistic model of how parameters influence performance and use that knowledge to decide which combinations to try next. Instead of blindly sampling, they learn from previous results, gradually focusing the search on the most promising areas. This makes Bayesian methods particularly useful when training each model takes a long time or when tuning many parameters at once.
In practice, you might start with a Random Search to explore the parameter space broadly, then refine the best results using a smaller Grid Search around the top-performing region. Throughout the process, it is helpful to use out-of-bag error or cross-validation as your evaluation metric, since both give reliable estimates of performance on unseen data. The key is to balance thoroughness with efficiency—there is no need to exhaustively test every setting when smarter search strategies can get you close to the optimum with far less effort.
From an interview perspective, being able to explain how you would tune a Random Forest is often more valuable than remembering exact parameter ranges. A strong answer shows that you understand the trade-offs between different search methods, know when to use them, and can justify your approach based on available data and compute resources.
Understanding Feature Importance
One of the biggest advantages of Random Forests, compared to many other ensemble methods, is that they not only make strong predictions but also provide insight into which features matter most. This makes them a great balance between predictive power and interpretability, especially when you want to understand what’s driving your model’s decisions.
After a Random Forest is trained, it can measure how much each feature contributes to reducing prediction error. The idea is simple: if a feature consistently helps the trees make better splits - that is, splits that result in more accurate or pure child nodes - then that feature is considered more important.
There are two main ways Random Forests measure feature importance.
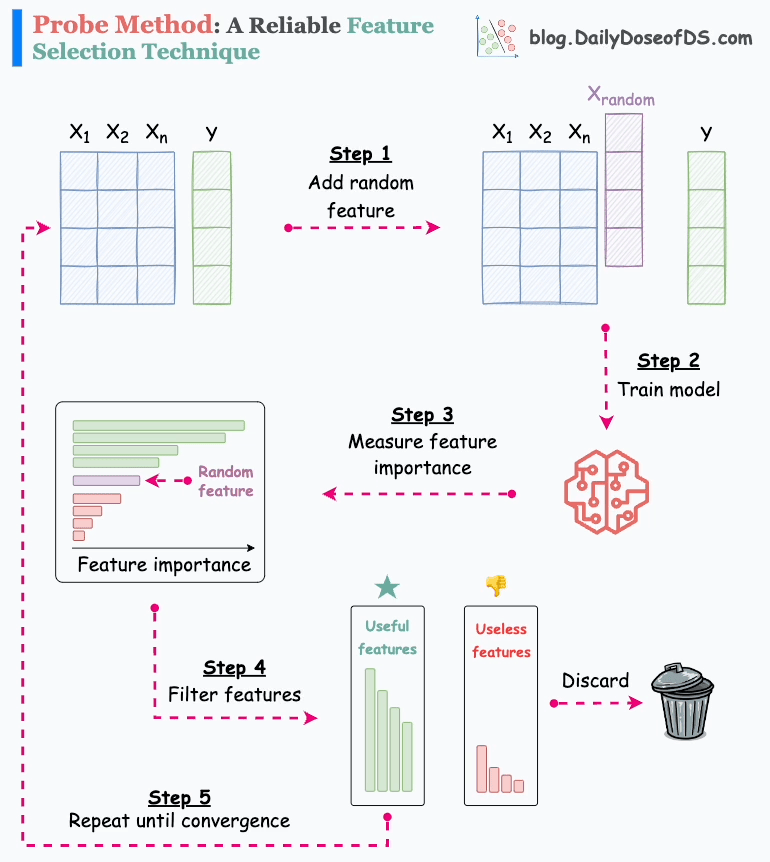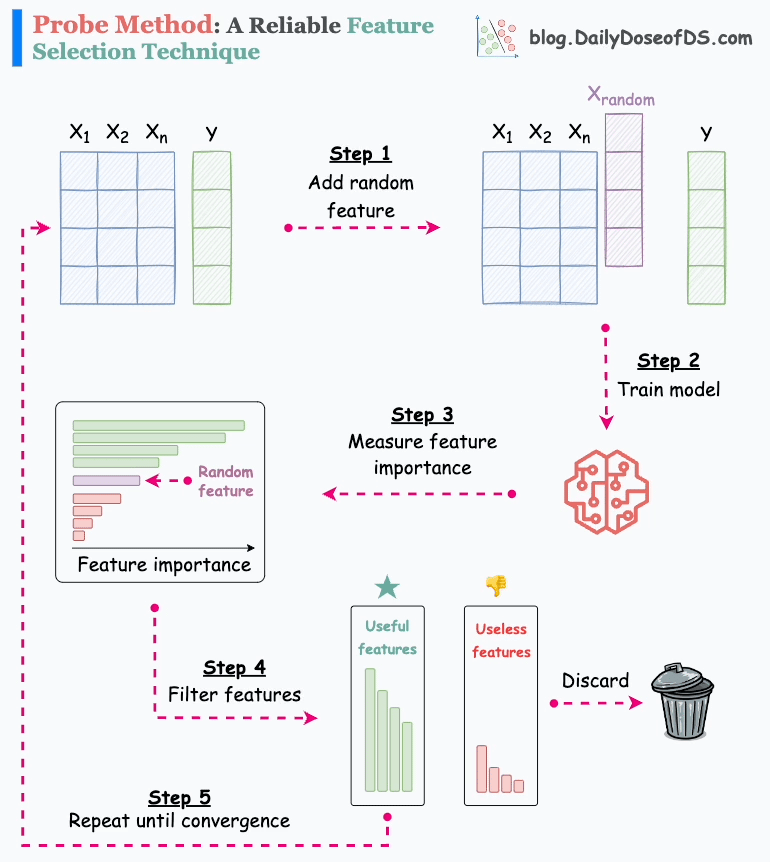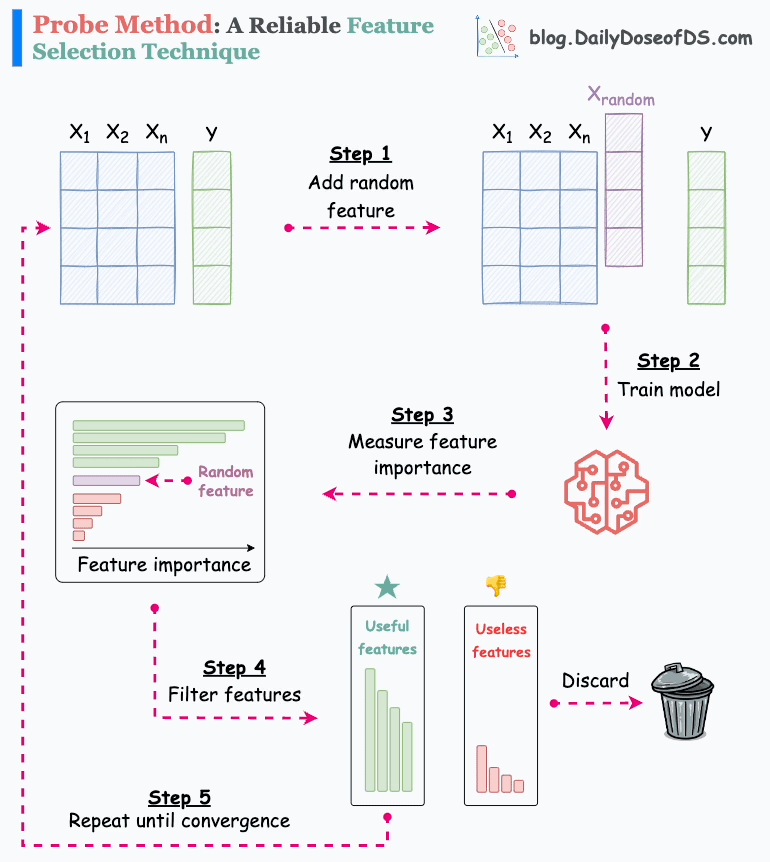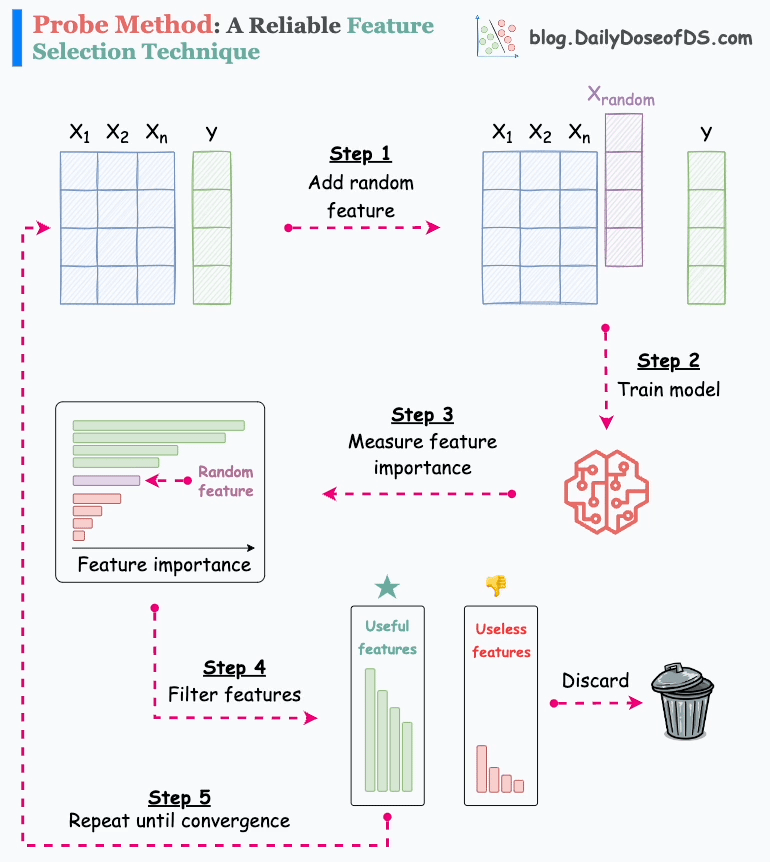
Impurity-Based Importance (Gini Importance)
This is the most common method and is calculated automatically during training. Each time a feature is used to split a node in a tree, the algorithm measures how much that split reduces impurity — for example, using metrics like Gini impurity or entropy for classification, or variance reduction for regression.
The total reduction in impurity that each feature contributes is then averaged across all trees in the forest. The higher the average reduction, the more important the feature is considered to be.
This method is very fast because it’s computed as part of model training, but it has one limitation: it can favor features with many unique values (for example, continuous variables) over categorical features with fewer distinct values. For this reason, it’s often a good idea to interpret these importance scores as relative indicators, not absolute truths.
Permutation Importance
Permutation importance is a model-agnostic approach that gives a more robust view of feature relevance. The idea is to randomly shuffle the values of one feature in the dataset and then measure how much the model’s performance drops as a result.
If shuffling a feature’s values causes the model accuracy to fall sharply, that feature must have been important. If there’s little or no change, the feature probably wasn’t contributing much to the predictions.
This method is slower than impurity-based importance because it requires re-evaluating the model multiple times, but it’s also more reliable and less biased toward features with many unique values.
Common Interview Questions on Random Forests
When interviewers ask about Random Forests, they are usually not just testing whether you can define terms. They want to see if you understand how and why the algorithm works, and whether you can apply that understanding to real-world problems. Below are some of the most common and insightful questions, along with guidance on what each is really testing.
What problem does a Random Forest solve compared to a single decision tree?
This question checks if you understand the motivation behind the algorithm. A good answer explains that a single decision tree tends to overfit because it has high variance. Random Forests reduce this variance by training many trees on different random subsets of the data and averaging their predictions. The key point is that combining multiple diverse models produces a more stable and accurate result.
How does Random Forest introduce randomness, and why is it important?
Here the interviewer is testing whether you know how diversity among trees improves performance. You should mention the two main sources of randomness: bootstrapping (random sampling of data) and random feature selection at each split. These make the trees less correlated, which reduces variance and improves generalization.
How do you interpret feature importance in a Random Forest?
This question looks for understanding beyond just the mechanics. Explain that feature importance measures how much a feature contributes to reducing prediction error across all trees. You can also mention the difference between impurity-based importance and permutation importance, and note that the latter is often more reliable for evaluating the true influence of features.
What is the out-of-bag (OOB) error, and how would you use it in practice?
This tests your grasp of how Random Forests can self-evaluate. You should describe how OOB samples are the data points not used in training a specific tree, and how these are used to estimate model accuracy without a separate validation set. It’s helpful to mention that OOB error is often close to cross-validation results and can be used for quick performance checks.
If your Random Forest is overfitting, what steps would you take to fix it?
This is an application question that reveals whether you can tune the model effectively. Explain that you can limit the complexity of individual trees by setting parameters like max_depth, min_samples_split, or min_samples_leaf. You can also reduce correlation among trees by lowering max_features, or add regularization by reducing the number of trees if the model is memorizing noise.
If your Random Forest is underfitting, how would you improve it?
The interviewer is checking whether you understand the bias side of the bias-variance tradeoff. You might increase the number of trees (n_estimators), allow deeper trees (max_depth), or reduce restrictions on splits. You could also check for data preprocessing issues, such as missing values or weak features.
How would you handle class imbalance in a Random Forest classifier?
This question connects theory to real-world data issues. Explain that you can use class weights (class_weight=’balanced’ in scikit-learn), resample the data (oversampling minority classes or undersampling majority classes), or evaluate performance with metrics like ROC-AUC, precision, recall, and F1 score instead of accuracy.
What happens if you increase the number of trees indefinitely?
This question tests your understanding of variance reduction and computational limits. Explain that more trees generally reduce variance and improve stability, but after a certain point the gains become minimal while training time and memory usage continue to grow. The OOB error or validation score will plateau, showing when additional trees are no longer useful.
How does Random Forest handle missing values or outliers?
Some interviewers ask this to see if you know about the model’s robustness. Explain that Random Forests are relatively tolerant of missing values and outliers because they average across many trees. However, it is still good practice to handle missing data with imputation and to check for extreme outliers that might distort splits.
How would you compare Random Forest with Gradient Boosting methods like XGBoost or LightGBM?
This question evaluates conceptual depth. A good answer highlights that Random Forest builds trees independently and averages them, which makes it easier to parallelize and less prone to overfitting. Gradient Boosting builds trees sequentially, where each tree corrects the errors of the previous one, which can lead to higher accuracy but requires more careful tuning and can overfit more easily.
So what are the final Takeaways?
Random Forests combine the simplicity of decision trees with the strength of ensemble learning. By training many trees on different random samples of the data and averaging their predictions, they reduce overfitting and produce stable, accurate models.
Their power comes from diversity. Each tree sees a slightly different view of the data and selects random subsets of features when splitting. This randomness keeps trees from becoming too similar and helps the forest generalize well to unseen data.
Beyond predictive performance, Random Forests provide built-in tools that make them practical and insightful. Out-of-bag samples offer an internal way to estimate accuracy without a separate validation set, while feature importance scores help identify which variables most influence predictions.
Tuning Random Forests involves balancing complexity and stability. Increasing the number of trees improves reliability, while parameters like max_depth, min_samples_leaf, and max_features control overfitting and bias.
In interviews, Random Forests are often used to test understanding of core machine learning concepts such as ensemble learning, bias-variance tradeoff, and feature importance. Being able to explain how and why they work shows that you understand both the intuition and the mechanics of modern ML models.
Wow, the way you highlighted how Random Forests combine the interpretability of decison trees with the power of ensemble learning really resonated with me.
ODB versus personal databasing. I like when entrepreneurship becomes group authenticity and recordable evidence of trial, trial and success! Scientific practices learning to expunge human errors!🎊🦖