
Data Science Case Study - Instagram For You Page
How to scope for the Explore page, figuring out features, choosing models, and designing the pipeline

This post will help you figure out how to approach a Data Science Case Study Question. The post will follow a multi-turn conversation that you will typically see in the case study format, but I will add some asides so that you have an understanding of the structure we are following as well.
Fig.1. System Design for Instagram ‘For You‘ Page
Interviewer: Design the ‘For You’ for Instagram.
Let me start with some clarifying questions before jumping into design. First, to make sure I understand the context - What’s the primary business or product goal here? Is it maximizing short-term engagement (likes, comments, watch time), or are we focusing more on long-term retention and user satisfaction?
Interviewer: Let’s assume it's the early stage of the app, so we are focusing on short-term engagement as the first priority, and then a second priority is user retention.
Quick next question: what scale are we operating at or planning for (rough numbers are fine) — for example, typical daily active users (DAU), posts uploaded per day, and average feed requests per second? This will help me pick retrieval sizes, index choices (FAISS vs simpler), and caching strategies. If in case we don’t want to be too specific, maybe we can just define it as small/medium/large, and I’ll assume reasonable defaults.
Interviewer: Let’s assume it’s for Instagram in somewhat the early stage, and go with medium
Quick single question before I pick retrieval and model choices: what latency SLO should we target for producing the next batch of Explore posts (99th-percentile
Interviewer: Instagram offers a real-time experience, so you can base it on that.
This is a sign from the interviewer that they want you to dive into the design element quickly, and that you can assume design elements based on how Instagram is currently.
Sounds good, then I’ll assume since we have a medium scale - we have a 200ms 99p tail and proceed. I’ll also assume that since we are prioritizing engagement, short-term videos would be more of a focus in terms of content type. I’ll also assume we have interaction signals typically seen in Instagram, like impressions, view/dwell time, clicks (taps), likes, saves, shares, follows, comments, and do we reliably log timestamps and device/context for each event?
Interviewer: Yes, this sounds reasonable
Sounds good. So we’re designing the Explore feed ranking system for Instagram, focusing on short-term engagement (likes, watch time, comments), with short videos prioritized, medium scale, and 200 ms latency.
Let me think for a few moments before discussing the design.
Its ok to think for up to 2 minutes, but taking more time could take the interviewer out of the process. We want to make sure we are thinking out loud, and showcasing our thought process as much as possible.
I would be designing a multi-stage system with candidate-generation/retrieval first and then a later stage to focus on ranking and serving. Ill start first by designing the candidate generation layer. Let me know if that sounds good
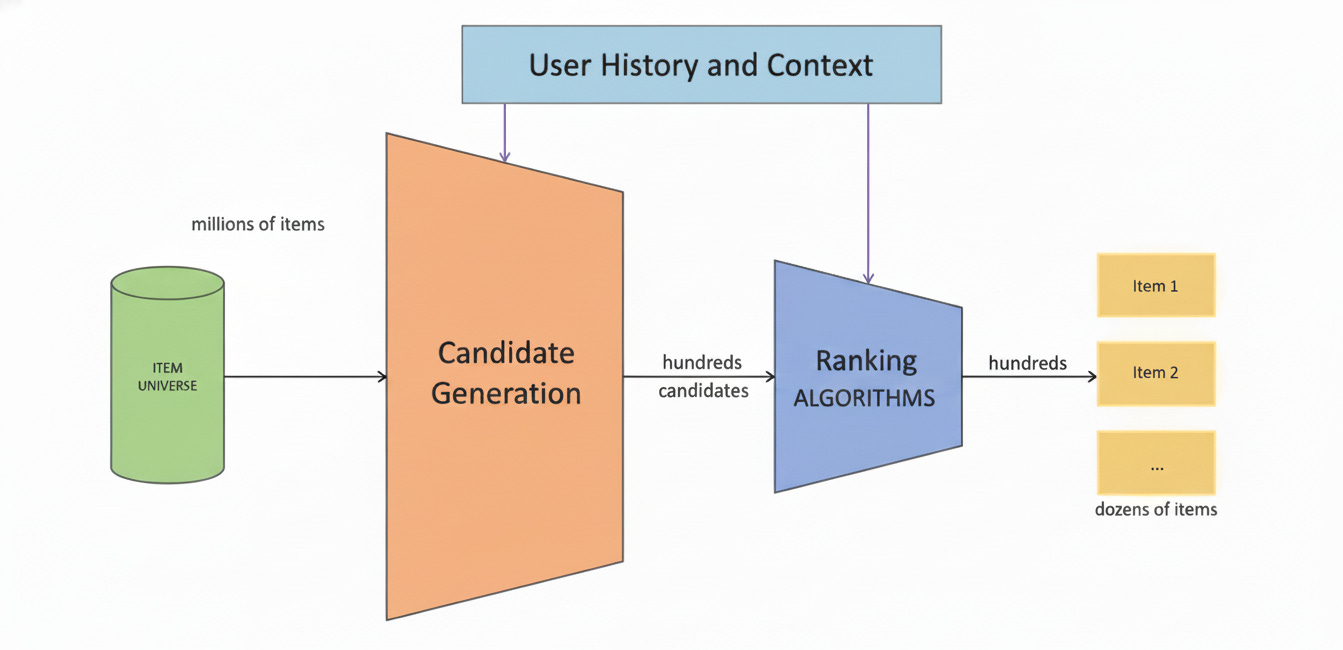
Fig.2. Design for Two-Stage Recommendation System
Interviewer: Why do you use a two-stage pipeline?
The first layer, retrieval, will focus on recall. It aims to narrow down millions of possible videos to a few hundred using lightweight approaches like embedding models and approximate nearest neighbor search. This keeps latency low and ensures we do not miss relevant content.
The second layer, ranking, focuses on precision. It uses richer features and more complex models, such as deep neural networks, to score and order those few hundred candidates. Because it works on a smaller set, we can afford to spend more computation per item.
Interviewer: You mentioned both precision and recall. Since we discussed focusing on engagement as the first priority, which metric —precision or recall — is more important?
If the primary goal is to maximize user engagement, then precision matters more than recall. The reason is that engagement depends on the quality of what users actually see and interact with, not on what we retrieved but never showed.
Interviewer: Ok, then, if you focus on only recall in the first layer, would it hurt precision in the second layer?
So, I will adjust my training process to account for this.
I will train retrieval with downstream-aware signals. I will not only train the retriever on shallow signals like views but also use labels derived from downstream engagement, like items that produced long watch.
I will also sample negatives that the ranker scored highly but that did not get engagement. I’ll add those as hard negatives when training the retriever so it learns the fine distinctions the ranker uses.
I’ll test the performance of these using canary A/B tests, and if in case it proves insufficient, I will use knowledge distillation where the expensive re-ranker scores are used as soft targets for a lighter retriever model. This encourages the retriever to surface candidates the re-ranker prefers while staying fast.
Interviewer: Sounds promising, let’s assume these adjustments do help the retrieval layers focus more on content that will have engagement downstream. Lets cover the details of the two-stage pipeline you mentioned.
Sounds good! To reiterate, the design we have is a retrieval layer and then a ranking layer. The retrieval layer is the first stage of the Explore feed ranking pipeline. Its goal is to collect a large and diverse set of potential short videos that could be shown to the user. These candidates are then passed to the ranking models that determine the final order.
Because we are focusing on short-term engagement and supporting infinite scroll, this retrieval system needs to work in real time and return results within about 200 milliseconds. It should balance personalization, freshness, and discovery.
To achieve that, the retrieval system draws content from several distinct sources, each optimized for a particular type of relevance.
The primary source of candidates comes from a user’s recent activity. We construct a session embedding that represents what the user has been watching in the last few minutes. This embedding is generated using either a recurrent neural network or a transformer model trained on sequences of viewed items. We then use this vector to query an approximate nearest neighbor index such as FAISS or ScaNN, which stores embeddings of all available short videos. Each video embedding is learned using a multimodal encoder that processes the visual, textual, and sometimes audio features of the video. The nearest neighbors in this space represent videos that are most similar to what the user has just watched. This step typically retrieves a few hundred highly relevant candidates and captures short-term intent very effectively.
The second source is based on the user’s long-term interests. While the session embedding focuses on immediate preferences, the long-term embedding reflects general content tastes built from weeks or months of interaction history. We train a dual-encoder model that produces user and video embeddings in the same latent space. This model is trained using a contrastive objective that brings the user and the interacted item closer together in the embedding space. Using this long-term user embedding to query the same ANN index provides another few hundred candidates that are consistent with the user’s overall interests.
A third source leverages the follow graph to keep some social relevance in the Explore experience. Even though this page is discovery-oriented, it can be valuable to occasionally show recent videos from people the user follows or from similar creators within the follow network. We can sample a limited number of recent videos from these connected creators and add them to the candidate pool. This strengthens the connection between discovery and social familiarity, which can improve engagement.
A fourth source focuses on trending and locally popular content. We maintain a cache of the most engaging videos in the past few hours using signals such as the rate of new likes or the velocity of views. This cache is updated frequently in a fast-access store such as Redis so that we can fetch around fifty of these videos almost instantly. Including this set ensures that users see what is popular in real time, which is especially important for short-form video platforms.
A fifth source comes from the most recent uploads. Newly posted videos often experience high early engagement, and the Explore page can accelerate that momentum. We therefore maintain a separate index of very recent short videos, typically uploaded in the past 10 to 30 minutes. We can sample a few dozen from this list and add them to the pool to keep the feed feeling fresh.
The final source introduces exploration. In addition to the sources that rely on user or population signals, we deliberately inject a small amount of randomness into the system. We can either sample randomly or use a contextual bandit algorithm that balances exploration and exploitation. The goal is to give exposure to new or underrepresented creators and to collect data about how users might respond to them. This prevents the model from overfitting to known content and helps maintain a diverse and evolving catalog.
All retrieved candidates are then passed through a series of fast filters. Hard filters remove blocked users, duplicates, or regionally restricted content. Soft filters apply quick heuristics to enforce basic quality and recency requirements. These operations are optimized to complete in a few milliseconds and ensure that only valid candidates reach the ranking layer.
Typically, each request retrieves between six hundred and eight hundred raw candidates. After filtering and deduplication, around three hundred are sent to the next stage for ranking. This number provides enough diversity for ranking while keeping computational costs low.
Interviewer: Ok, I made a few notes and have a question on some aspects. First, you mentioned that retrieval needs to operate in a few 100ms. How would you facilitate pulling all this in that time?
To make this retrieval layer efficient and fresh, we maintain two indexing strategies.
The first is an incremental update that adds new short videos to the index every few minutes. Trending and recency lists are refreshed continuously from real-time data pipelines. This can be used to pull recent uploads, trending uploads, or uploads from the accounts the user follows. Each new short video goes through a lightweight preprocessing step that extracts frames, audio features, and text and produces the initial item embedding. This streaming embedding is produced within seconds to a couple of minutes of upload, so the new item can appear in recency and exploration pools. Short videos often get small updates in metadata and early engagement signals. Every few minutes or every 5 to 15 minutes, you run a micro-batch pipeline that recomputes embeddings for very recent items and items with rapidly changing metadata.
The second is a nightly rebuild for at least large swaths of content to incorporate model updates and richer offline features. Full model retraining and re-embedding for the entire corpus happens on a slower cadence such as weekly or biweekly depending on model drift.
Interviewer: Ok, those two sound optimal. You also mentioned using contextual bandits for exploration. Could you explain how this works?
A contextual bandit is a learning method to balance two competing goals in recommendations. The first is exploitation, which means showing the content that we already believe the user will like based on what we have learned so far. The second is exploration, which means occasionally showing new or uncertain content so that the system can learn and improve over time.
At a high level, the system works like this. When the Explore feed needs to pick a video to show, it first looks at the user’s context and all the available candidate videos. For each candidate, it predicts an expected reward, which can be thought of as the likelihood of the user engaging with it. If the system always chose the item with the highest predicted reward, it would be doing pure exploitation. This might look good in the short term but over time the model would stop learning about new or less familiar content. It would only reinforce its current beliefs and could easily get stuck showing similar types of videos repeatedly. That is where exploration comes in.
Exploration is introduced by intentionally selecting some items that the model is less certain about. There are several strategies for this. A simple one is epsilon-greedy, where the system chooses the top predicted item most of the time but with a small probability, say five percent, it randomly picks a different item. This random chance ensures that new creators or topics get occasional exposure.
For more on contextual bandit, check out this resource - https://towardsdatascience.com/an-overview-of-contextual-bandits-53ac3aa45034/
Interviewer: If contextual Bandit is to help discover new content - why not put it in the ranking layer, since it decides what is finally shown to the user?
The retrieval layer is responsible for deciding which candidates even get considered by the ranking models. At this stage, the system needs to balance between showing content that is already known to perform well for the user and discovering new content that might perform well but has not yet been tested.
This is exactly the type of decision contextual bandits are designed for. They help decide which content sources or candidate types to pull from for a given user context. For example, the retrieval system might choose between fetching from similar-user embeddings, trending videos, or completely new creators. Each of these options has a different level of uncertainty about how engaging the content will be.
By applying contextual bandits here, we let the system experiment at the boundary of what it already knows. The cost of exploration at this stage is relatively low because the bandit only affects which candidates go into the pool, not necessarily what the user ultimately sees. The later ranking stages can still filter and order the final feed to protect user experience. This makes the retrieval layer a safe and effective place to learn.
There are other questions the interview can focus which are focused more on how well they understand models/algorithms. E.g., How does the contextual bandit algorithm work? Why do you want to use RNN/transformer for the short-term interest embedding? Why use a dual-encoder for long-term interest? How to samle videos from the accounts that you follow etc.
However in the interest of keeping the post short (relatively), ill skip this. Comment down below which one you want to know more about!
Interviewer: Ok, let’s move to the ranking layer.
The ranking system operates in two stages: a lightweight first-stage ranker and a more complex second-stage re-ranker. This two-tier structure allows us to balance model complexity and inference latency. The first model is designed for speed and recall, while the second model focuses on precision and personalization.
In the first stage, we typically use a fast machine learning model such as a gradient boosted decision tree (GBDT) implemented with XGBoost or CatBoost. The model scores each candidate based on simple, precomputed features. These features include basic user activity statistics, creator-level engagement rates, recency, and historical popularity. The goal is to filter the few hundred retrieved candidates down to about fifty or one hundred that are most likely to drive engagement. This first stage must execute in tens of milliseconds so that the pipeline remains within the overall latency constraint.
Once the first-stage ranker produces a shortlist, the second-stage re-ranker performs a much deeper scoring pass. This model can be a neural network designed to capture complex interactions between the user, the video, and the surrounding context. A common architecture is a multi-task feed-forward network or a transformer-based model that takes both static features and sequential signals as input. The model outputs multiple engagement probabilities, such as the probability of a like, a long watch, a share, or a follow. These predicted outcomes are then combined into a single engagement utility score that represents the expected short-term value of showing that video to this user.
Because our primary objective is short-term engagement, this utility score can be defined as a weighted combination of engagement actions.
For those looking to understand different recommendation system architecture check out this blog - https://theaisummer.com/recommendation-systems/
Interviewer: You mentioned a multi-task model. How does it work?
A multi-task model is a single model that predicts several related outcomes at the same time instead of training one model per engagement signal. In a feed like Instagram Explore, a user can like, comment, share, save, or simply watch a video for a long time. All these actions are connected, so it makes sense to learn them together.
The idea is that the model has a shared part that learns general patterns about how users interact with content, and then separate smaller parts, called heads, that specialize in predicting specific actions. The shared layers might learn that a user tends to engage more with food videos, or that visually bright videos perform better on weekends. The task-specific heads then use that shared understanding to predict particular probabilities, such as how likely a user is to like or comment on a given video.
Training happens jointly. The model calculates a loss for each task, for example one loss for predicting likes and another for predicting watch time. It then combines them, usually as a weighted sum, and updates the network so that the shared layers improve across all tasks at once. This means the learning from common signals, like likes and watch time, helps improve predictions for rarer actions, like shares or follows.
Once trained, the model outputs several predictions for each video: a probability of a like, a probability of a comment, an expected watch time, and so on. These predictions can be combined into one overall engagement score that represents how valuable the video is for the user. For instance, the system might assign higher weight to long watch time and lower weight to likes if the goal is to keep users more engaged over time.
The main reason to use a multi-task setup is that it improves data efficiency and generalization. Engagement actions share underlying factors, so it is wasteful to train completely separate models. This approach also produces more balanced recommendations.
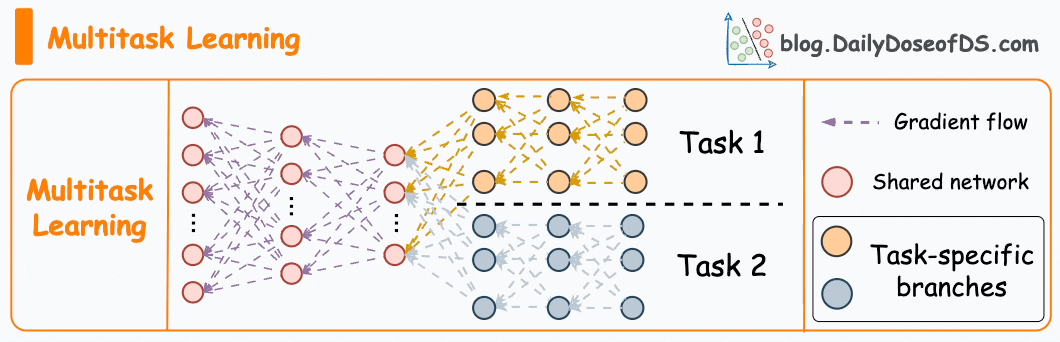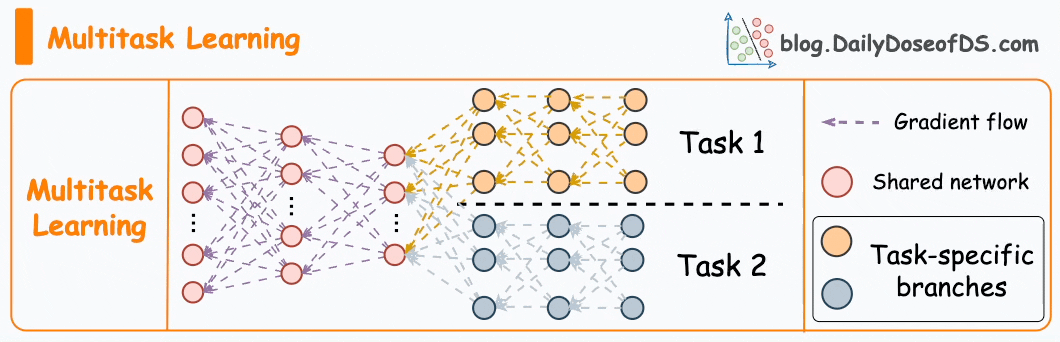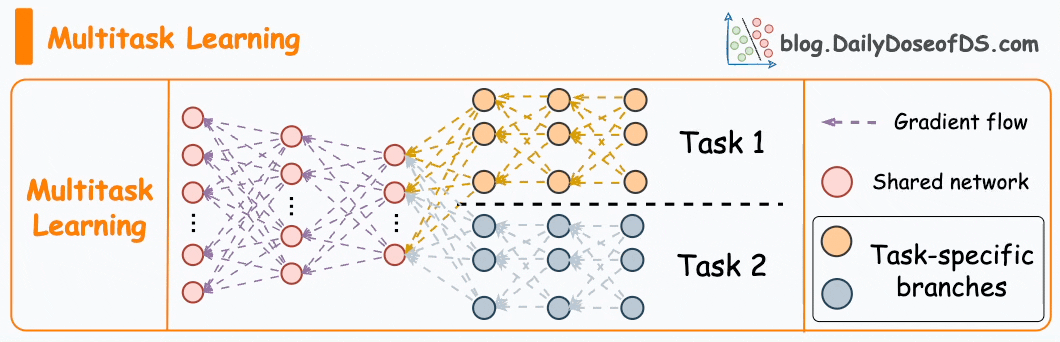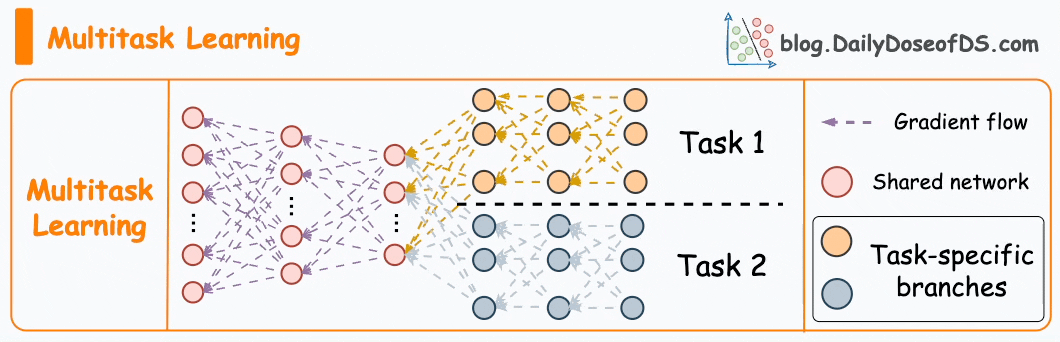
Fig. 3. Multi-Task Learning Model
Looking to land your next role? The two hurdles you need to tackle are callbacks and interviews.
To get a callback, make sure your resume is well-written with our resume reviews, where we provide personalized feedback - https://topmate.io/buildmledu/1775929
To crack interviews, use our mock interview services. Whether it’s DSA, ML/Stat Theory, or Case Studies, we have you covered - https://topmate.io/buildmledu/1775928

Don’t forget, for everything ML - Checkout BuildML
https://topmate.io/buildmledu
Interviewer: How about business rules? How can we adjust the recommendations to adjust recommendations for certain business goals that could be separate from customer behaviour?
Businesses often have additional goals such as promoting new creators, increasing ad impressions, ensuring safety, or highlighting specific content categories. These are handled through what we call business rules or policy constraints that sit alongside the machine learning models.
The general idea is that the model predicts what users are most likely to engage with, but the final ranking is adjusted to satisfy higher-level business objectives. This is usually done in the post-ranking or blending stage, after the model has assigned scores to each candidate.
There are a few common ways to apply business rules.
The simplest method is rule-based reweighting. For example, if the company wants to promote new creators, we can multiply their model score by a small boost factor, such as 1.1 or 1.2, so their content has a slightly higher chance of appearing near the top. Similarly, if there is a campaign to highlight eco-friendly content, we can give those videos a positive weight for a certain period. These boosts can be conditional on user segments or geography so that the impact is targeted rather than global.
A second method is quota or constraint-based ranking. In this case, instead of adjusting scores, we impose explicit limits or minimums. For example, we might require that at least ten percent of feed impressions come from new creators, or that no more than one video per creator appears in the top twenty results. This can be implemented as a constrained optimization problem, where the goal is to maximize engagement while satisfying fairness or diversity constraints. Efficient algorithms such as constrained linear programming or greedy re-ranking can enforce these rules in milliseconds.
A third approach is to integrate business objectives directly into the model’s utility function. For instance, if a business wants to balance engagement with ad revenue, the model’s final score could be a weighted sum of engagement probability and predicted ad value. This allows business goals to influence ranking in a smoother, data-driven way rather than hard rules. The challenge here is choosing the right weights and making sure the system still feels natural to users.
Interviewer: How would you measure the impact of the model?
First, I would start by defining the primary success metrics. Since this Explore model focuses on engagement, the main goal is to improve user actions such as watch time, likes, comments, and saves. However, the metric should reflect overall user value, not just one behavior. A good composite engagement metric could be a weighted sum of meaningful actions, where long watch time or saves are given higher weight than simple likes.
Second, I would track guardrail metrics to make sure the model does not optimize engagement at the cost of long-term health. These include retention, time between sessions, diversity of content exposure, fairness across creators, and safety indicators such as impressions of flagged content. The principle is that any model change must improve the primary metric without hurting guardrails beyond a small tolerance.
Third, I would design a strong experiment. The most reliable way to measure impact is through an A/B test or online controlled experiment. Users would be randomly assigned to either the new model or the current baseline. If no baselines exist, I would sample recent videos from accounts the user follows, or from trending videos. This randomization ensures that any difference in engagement or retention comes from the model itself and not from seasonality, user mix, or content changes.
The experiment should run long enough to capture stable behavior. For short-term engagement metrics, one to two weeks may be sufficient. For retention or creator fairness, four to six weeks is safer.
For more on A/B testing, check out this free course - https://www.udacity.com/course/ab-testing--ud257
Interviewer: Can you talk about how you would define how long the test should run, and what kind of impact would be significant?
To decide how long a test should run, I’d look at two things: how much data we need for statistical confidence, and how long it takes for user behavior to stabilize.
First, the data side. The length of a test depends on three key factors:
The baseline rate of the metric we’re measuring, such as a 5 percent click rate or average 30 seconds of watch time.
The minimum detectable effect (MDE) — the smallest change we care about and want to detect. For example, maybe we want to detect at least a 10 percent lift in clicks, from 5 percent to 5.5 percent.
The traffic volume, or how many users or impressions we get each day.
Once we know these numbers, we can use a simple sample size formula. For a binary metric like click rate, the formula tells us how many users we need per group to detect that change with 95 percent confidence and 80 percent power. In practice, with a 5 percent baseline and a 10 percent relative lift, we’d need about 30,000 users per group.
If our app has 1 million users per day and we split traffic evenly, we’d reach that sample size in less than a day. But we should still run the test for at least a full week to capture normal variations across weekdays and weekends, and to smooth out novelty effects. For longer-term outcomes like retention, we would extend the experiment to cover the observation window — for example, 7 days for 7-day retention, or 28 days for monthly retention.
Second, the business side. Not every statistically significant change is meaningful. We define in advance what effect size actually matters to the business. For engagement metrics like watch time or likes, a 1–3 percent lift can be meaningful at large scale. For retention, even a 0.5 percentage point increase can be important because it compounds over time.
Interviewer: That sounds good. I think that’s all the questions I had. Any questions you have for me?
And that’s it! Hope this provides you with an idea of how to approach case study rounds. Make sure to subscribe for more deep dives!