
Data Science Case Study: Design a RAG System for a Private Corpus
Answering the hottest system design question right - how do build your RAG system

This post will help you figure out how to approach one of the most common Data Science / ML System Design Case Study currently - “How do you design a RAG system“.
The post simulates a real interview and as such follows a multi-turn interview conversation. I’ll add sidebars so you understand the structure and strategy behind each move. Now, lets get to the question!
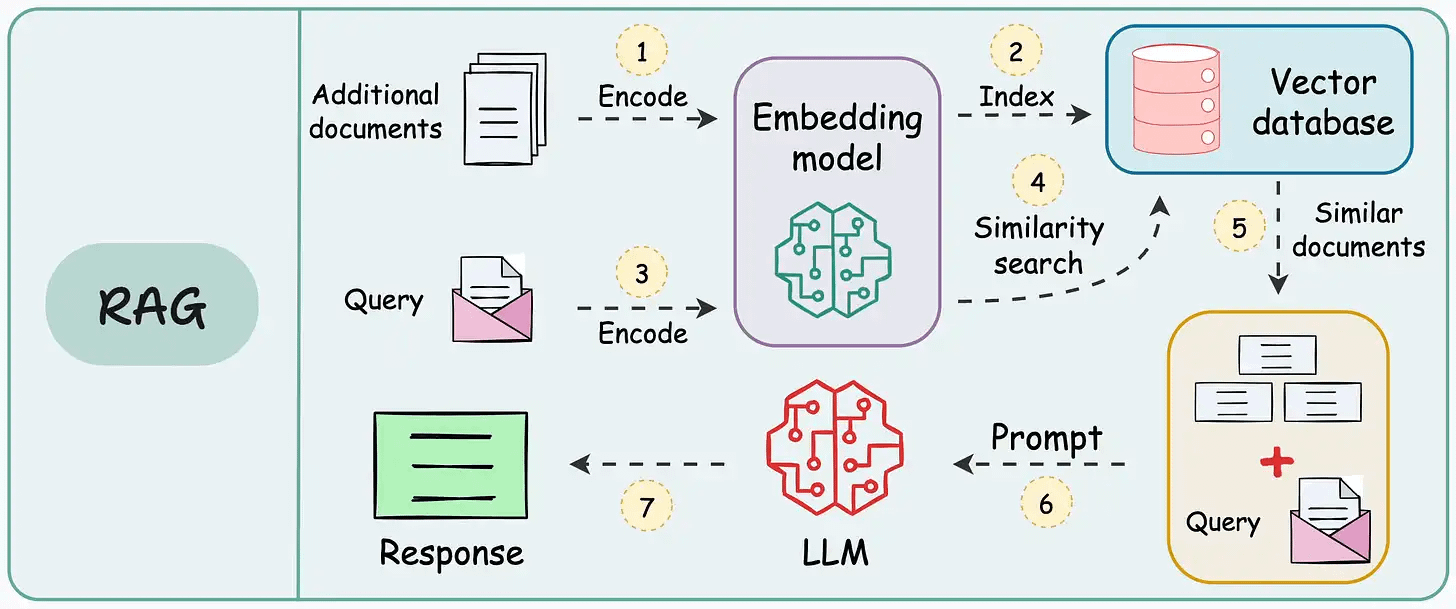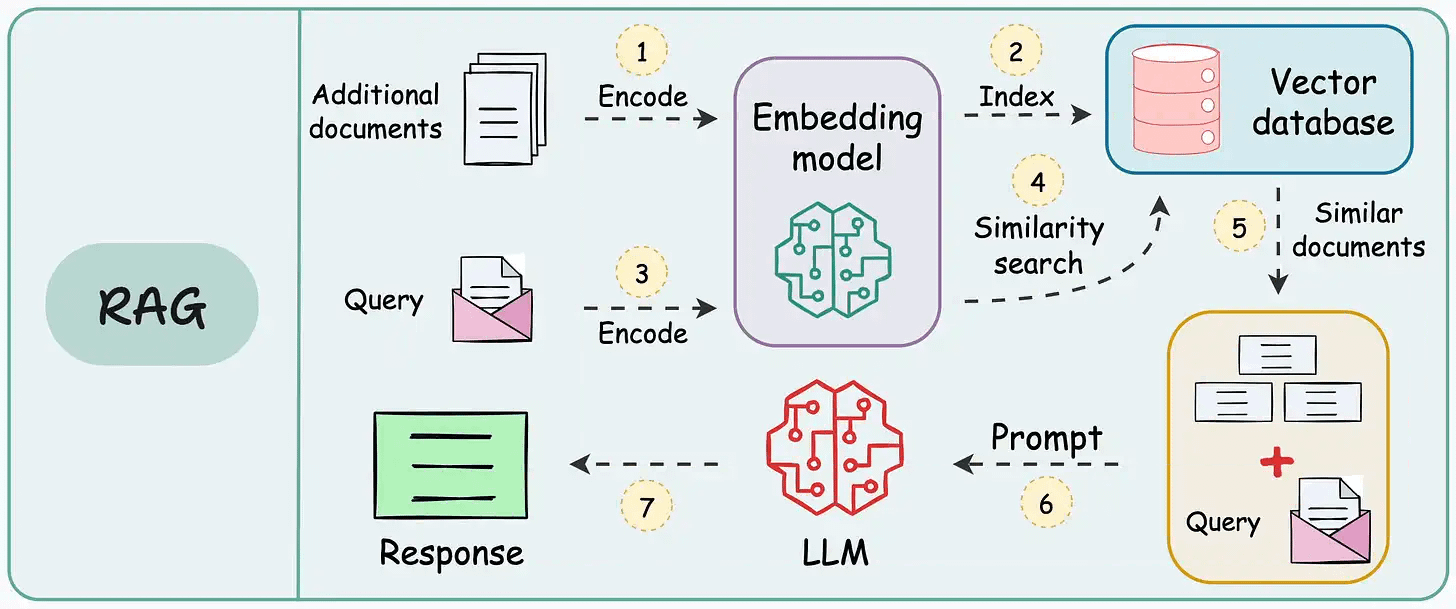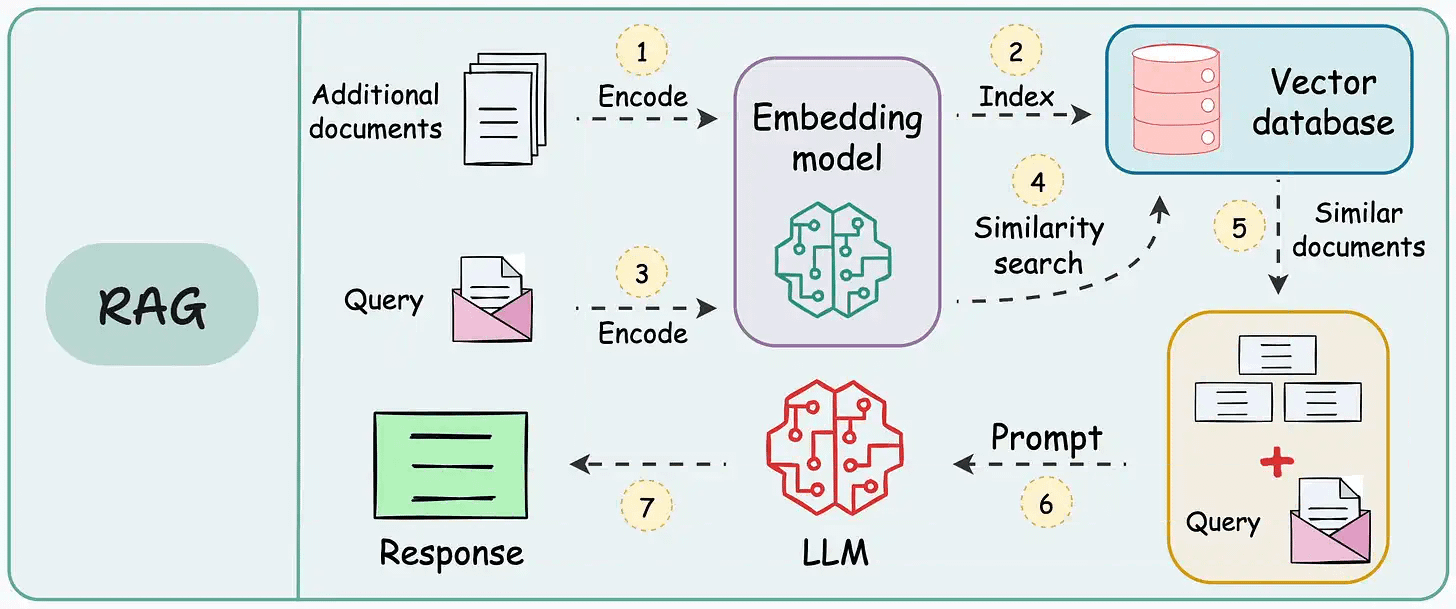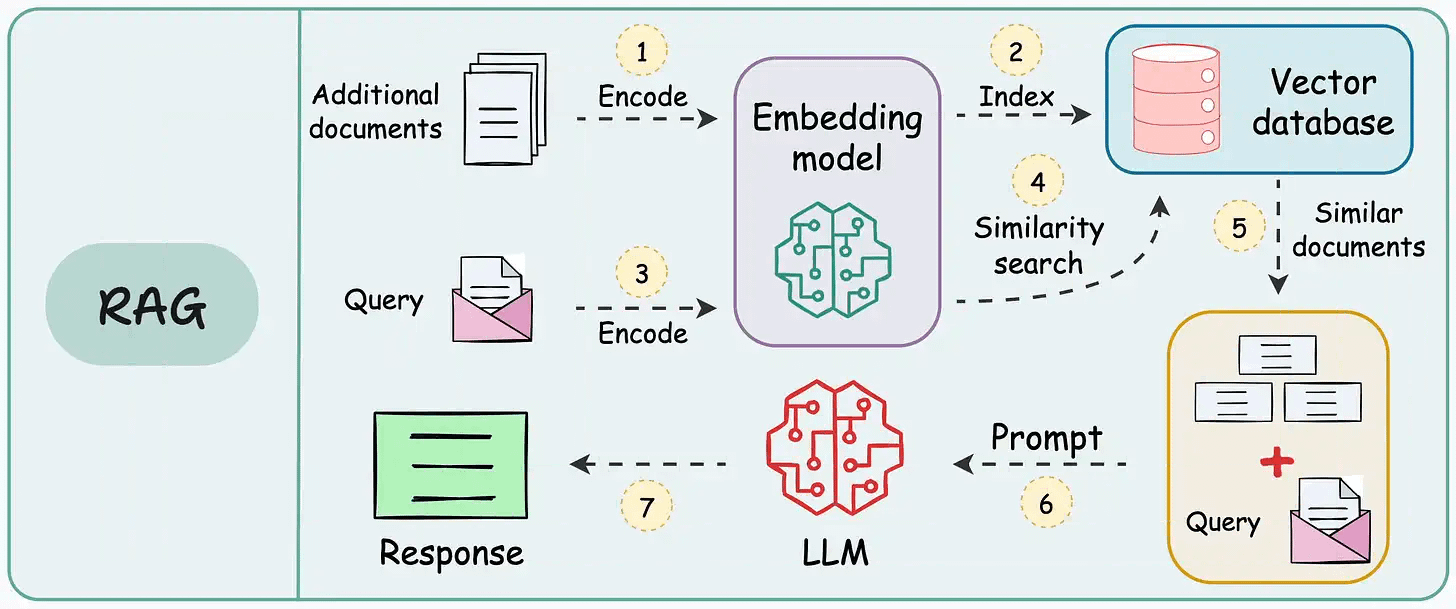
Interviewer: Design a Retrieval-Augmented Generation (RAG) system that answers user questions using a private corpus i.e. internal docs, PDFs, and knowledge base articles.
Need more questions? Make sure to checkout PracHub
Part 1: Clarifying Questions
SideBar: Before diving into any design, the goal is to anchor on objectives, constraints, and scale. This signals structured thinking and prevents you from solving the wrong problem.
Candidate: Sure. Before I start sketching anything out, I’d like to ask a few clarifying questions so I’m not designing in the dark.
The first thing I want to understand is who’s actually using this and what they’re trying to do. Is this an internal tool (think employees asking questions about company policies and engineering runbooks), or is it more customer-facing, like a support bot? Because the failure modes are really different. If a customer gets a wrong answer, that’s a brand problem. If an employee gets a wrong answer about an HR policy, that’s an operational problem. The stakes and the acceptable latency are pretty different.
Interviewer: Think of it as internal. Employees asking questions using internal documents: HR policies, engineering runbooks, product specs.
Candidate: Got it. Second thing: I want to get a rough sense of the corpus size and how live it is. Are we talking hundreds of documents that barely change, or is this a large, actively updated knowledge base?
Interviewer: Mid-sized enterprise. Call it 500,000 documents. Semi-static, updated or added to weekly, not in real time.
Candidate: And the last thing I want to pin down before we go further: what’s the latency expectation and how much does the business care about accuracy versus coverage? Specifically, is it worse to give a wrong answer or to say “I don’t know”?
Interviewer: Synchronous chat, under 5 seconds end-to-end. And wrong answers are worse than no answers. This is enterprise, and incorrect information causes real operational damage.
Sidebar: Three clarifying questions is the sweet spot. You’ve locked in (1) the use case and failure mode, (2) corpus scale and dynamics, and (3) the latency and quality tradeoff. Don’t over-clarify. The interviewer wants to see you design. Summarize before moving on.
Candidate: Perfect. So just to make sure we’re aligned before I start: we’re building an internal enterprise knowledge assistant, the corpus is around 500K documents updated weekly, we need to respond within 5 seconds, and we should always prefer saying “I don’t know” over guessing. Got it. Let me think for a second before I walk you through how I’d approach this.
Sidebar: It’s fine to pause for 30 to 60 seconds. Narrate your mental model out loud as you think. Something like “I’m thinking about this as two separate systems, one that runs offline and one that serves requests online...” This shows process, which is what the interviewer is evaluating.
Part 2: System Design
Candidate: Ok so the way I’d frame this at a high level: there are really two distinct systems here, and I think it’s important to keep them separate from the start.
The first is an offline indexing pipeline. It’s responsible for taking raw documents, processing them, turning them into chunks, embedding those chunks, and building a searchable index. This runs on its own schedule (weekly, in our case) and has a very different computational budget than anything real-time.
The second is an online serving pipeline. This is what runs every time a user submits a question. It handles query understanding, retrieval, re-ranking, context assembly, generation, and guardrails.
The reason I want to keep these separate is that conflating them leads to systems that are either too slow, because you’re trying to do heavy offline work in a real-time path, or too stale, because you’re cutting corners on indexing to hit latency targets. Keeping them clean makes each easier to optimize and debug independently.
Should I walk through the offline side first?
Interviewer: Yes, go ahead.
Text Pre-processing
Candidate: Alright, so let me start at the very beginning of the offline pipeline, which is document ingestion.
Documents are going to arrive in a mess of formats: PDFs, Word docs, HTML pages, Markdown files, plain text. I’d use a document parsing layer to extract clean text and structure from all of these. Something like Apache Tika, with custom parsers for anything particularly unusual.
Now, PDFs are the case I’d stress test the hardest. Naive PDF text extraction, where you just pull the raw text layer, produces garbage when the document has a complex layout. Tables get linearized incorrectly, footnotes appear in the middle of a paragraph, section headers run into body text. For an enterprise corpus, that’s a serious problem because tables often contain the most precise, actionable information e.g. compensation bands, error code definitions, SLA thresholds etc. If you corrupt those at parsing time, you can’t fix them downstream. I’d use a layout-aware parser that actually understands document structure, and tables specifically get converted into structured markdown so they’re retrievable.
At this stage I’d also extract and preserve document-level metadata: title, author, department, creation date, last-modified timestamp, document type, and access permissions. That metadata becomes a filtering layer later.
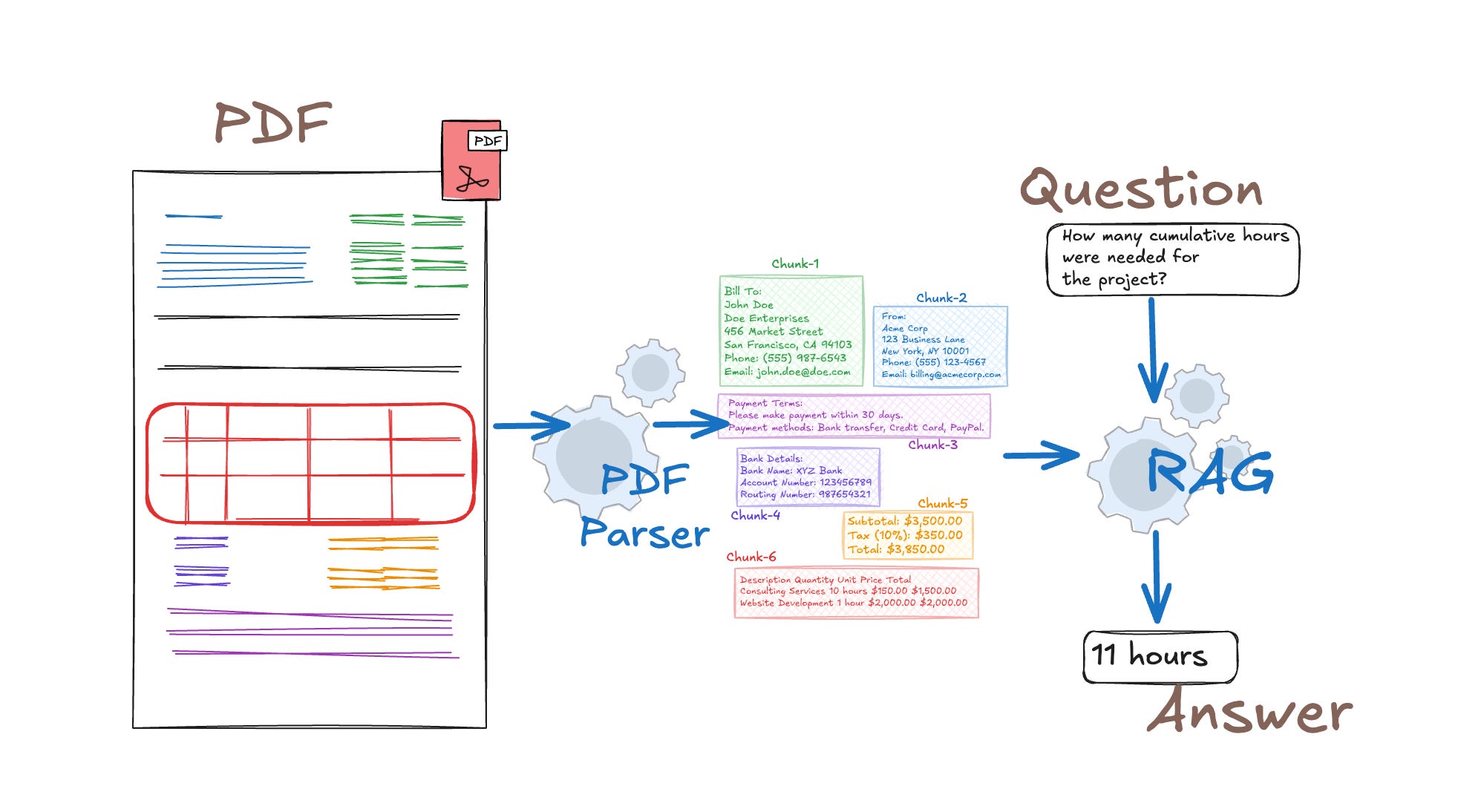
Interviewer: What about documents that are scanned images with no embedded text at all?
Candidate: Yeah, that’s a real issue for older enterprise corpora. Scanned HR files, legal documents, that kind of thing. For those I’d add an OCR stage before parsing. I’d use something like AWS Textract or something similar because they have much better layout understanding, particularly for forms and tables in scanned documents. The OCR output feeds into the same downstream pipeline. I’d also tag those documents with a source type flag so quality checks downstream can treat them separately. OCR-extracted text has higher noise and you want to know that when you’re debugging retrieval failures.
Interviewer: Ok, sounds reasonable. Go ahead.
Chunking
Candidate: Ok, so once the text is extracted and cleaned, the next step is chunking, and I think this is actually where most RAG systems go wrong without realizing it. The retrieval quality you can get is fundamentally bounded by how good your chunks are.
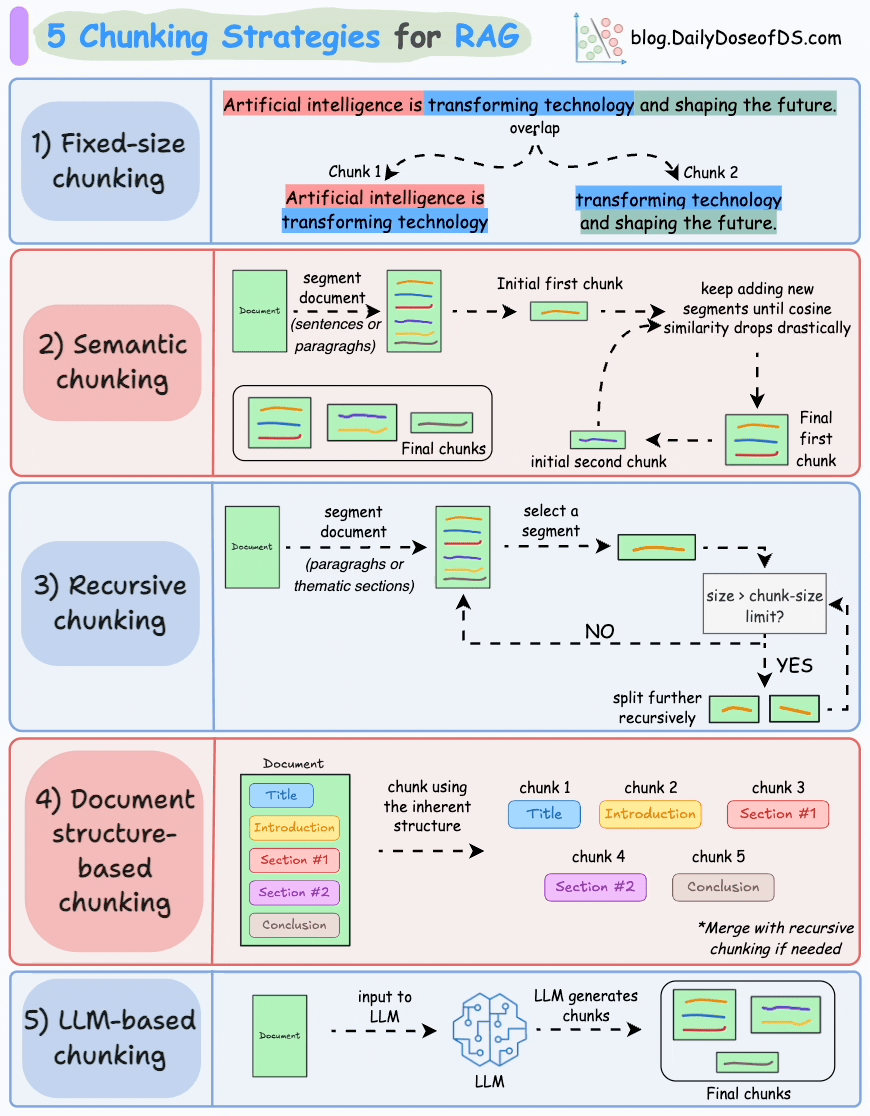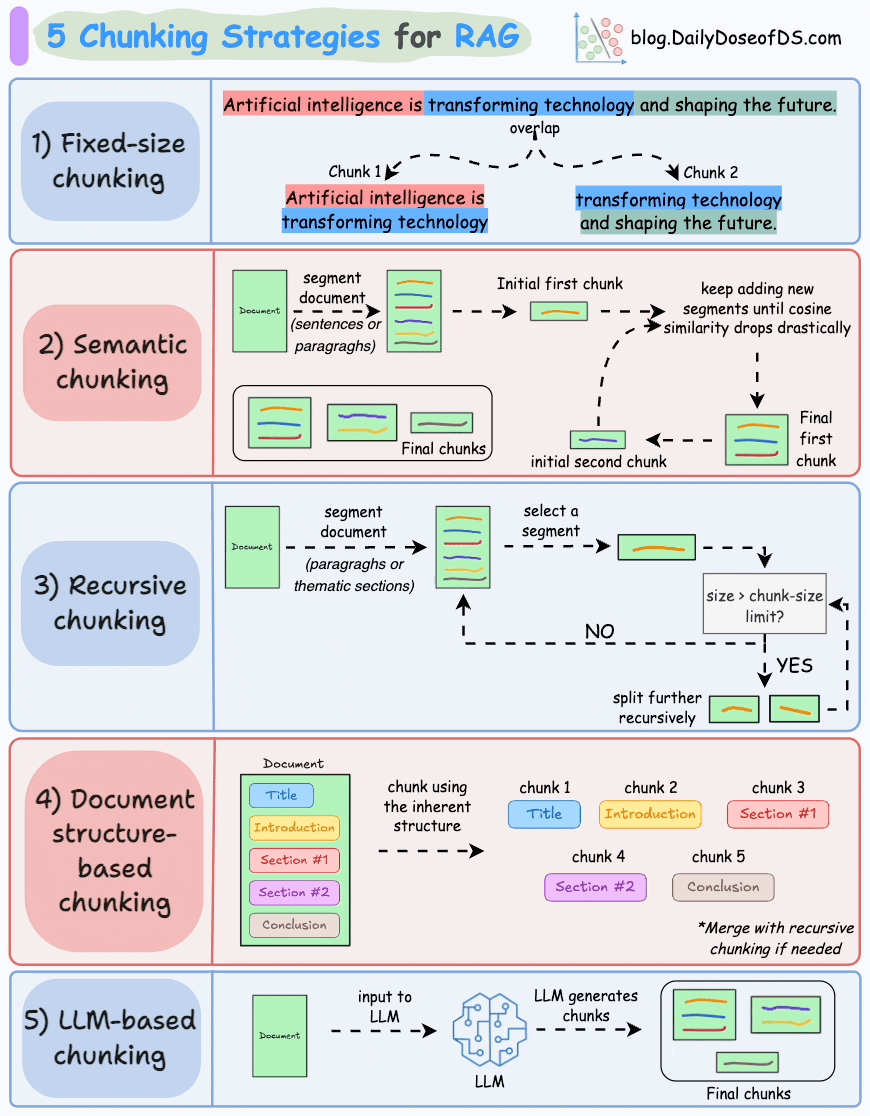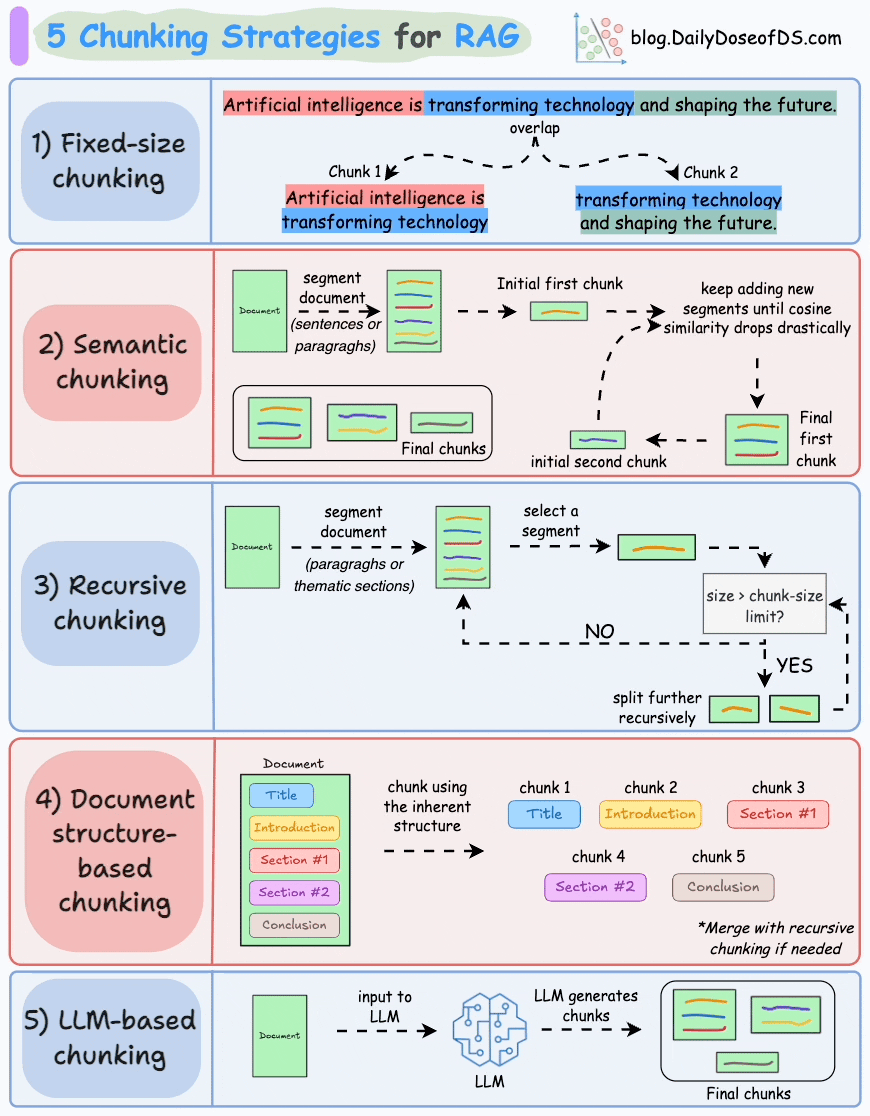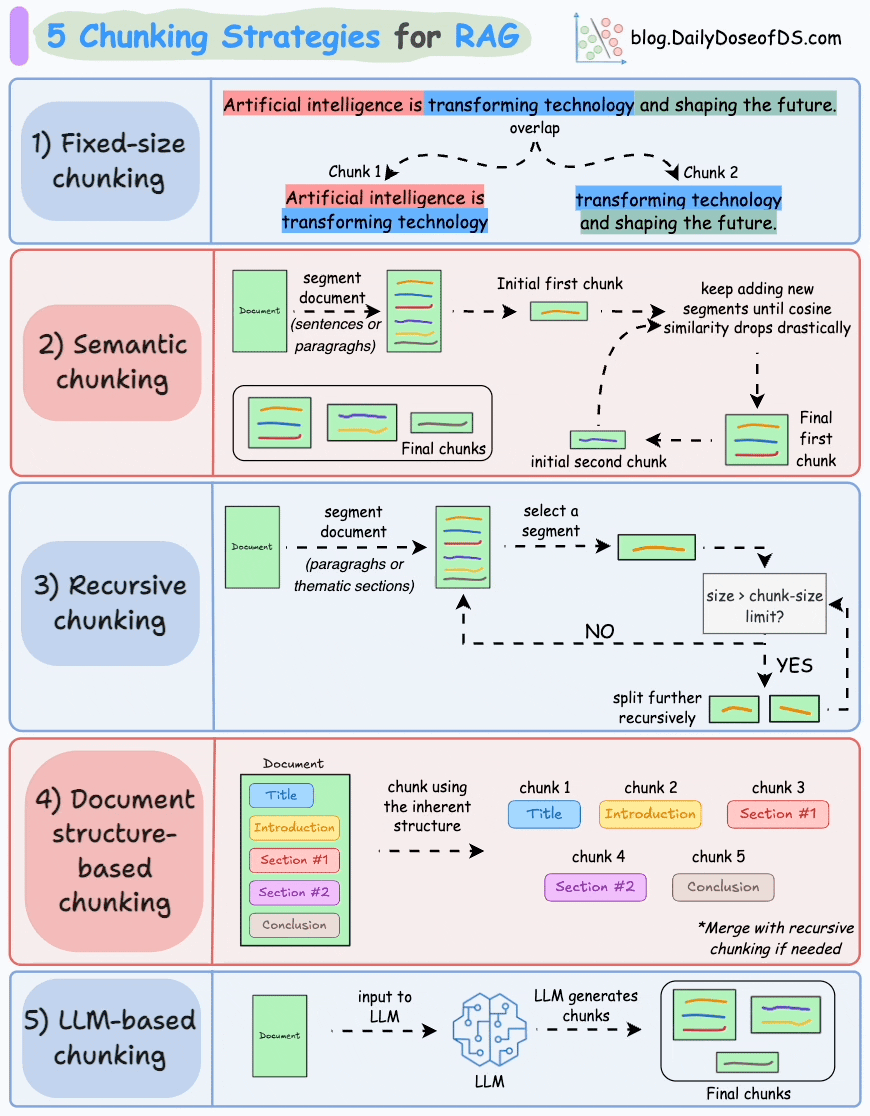
The basic tension is that small chunks are precise but lose context, and large chunks have context but dilute the retrieval signal. So rather than picking one size and tuning it, I’d go with a hierarchical strategy across three levels.
At the finest level, sentence-level chunks of roughly 100 tokens. These are good for narrow fact-seeking queries where you want a precise match. At the middle level, paragraph-level chunks of 300 to 500 tokens, which is the primary retrieval unit for most questions. And at the top level, section-level chunks of around 800 to 1000 tokens, which I use not for retrieval but for context expansion after a hit is found. I’ll come back to that.
A few important details. Adjacent chunks overlap by about 10 to 15% so that relevant context doesn’t fall into a crack between two boundaries. Chunk boundaries should respect document structure, meaning I would never split mid-sentence, ideally not mid-paragraph, and every heading gets included at the top of the chunk it introduces so the retriever has topic context. Every chunk also stores a pointer back to its parent document, its position in the document, and the IDs of its neighboring chunks.
Interviewer: Why three levels? Can’t you just pick one good size and tune it?
Candidate: The problem is that different queries genuinely need different granularities. “What’s the maximum reimbursement for a domestic flight?” That’s a narrow factual lookup, you want a tight, precise chunk. “Explain the company’s approach to performance reviews” needs more surrounding context to produce a coherent answer, a small chunk is going to feel incomplete. A single fixed chunk size ends up being a compromise that’s mediocre at both. The hierarchical approach lets the retrieval layer hit at the right granularity, and the context expansion I mentioned lets generation work with enough context regardless of where the match was found.
Interviewer: How would you actually evaluate whether your chunking is good? It seems hard to measure.
Candidate: It is hard to measure, and most teams skip it, which is exactly why they can’t diagnose retrieval failures properly when they happen. I’d run three checks. The first is a boundary sensitivity test: take a set of queries with known answer spans and verify the answer text is fully contained within a single chunk rather than split across two. If answer spans frequently straddle boundaries, the chunking is misconfigured. The second is a coherence audit: sample a few hundred chunks and have a human or an LLM judge evaluate whether each one is semantically self-contained. A chunk that starts mid-argument with no context is a red flag. The third is a table fidelity check: for documents with known tables, verify the extracted chunk actually represents the table correctly. These are offline audits, not production metrics, but they’re essential before any launch and after any change to the parser or chunking logic.
Interviewer: Ok, sounds good. Lets move onto to the next portion of your design.
Representation and Indexing
Candidate: Ok, so now the chunks exist. The next question is how we represent them numerically and build something we can search.
Each chunk gets encoded into a dense vector using a text embedding model. For enterprise use I’d default to something like OpenAI’s text-embedding-3-large. If the corpus is highly domain-specific (i.e.heavy legal language, medical terminology, or deep engineering jargon), which in this case it might be, , I’d consider fine-tuning the embedding model on in-domain query-passage pairs using a contrastive objective, because off-the-shelf models can underperform on specialized vocabulary.
Once we have the vectors then we need to build an index - which is the next critical decision. I wouldn’t just build a single dense vector index. I’d build two parallel indexes: a dense index using HNSW in a vector database, and a sparse BM25 index in something fast like Elasticsearch. The reason you need both is that dense retrieval is great at semantic similarity but it genuinely struggles with exact matches: product codenames, error codes, precise legal citations, internal system identifiers. A user searching for “error ER-4412” might get back documents semantically about error handling in general rather than the one document that actually defines that specific code. BM25 is immune to that because it’s purely lexical. The cost of maintaining a sparse index is low, and the coverage improvement on exact-match queries is substantial.
Interviewer: What happens when you want to upgrade to a newer, better embedding model? You already have 500,000 documents indexed.
Candidate: That’s a real operational headache. When the embedding model changes, the embedding space changes, which means the old index is incompatible with new query embeddings. You have to re-embed and re-index the entire corpus. For 500K documents with multiple chunks each, that’s potentially millions of embedding calls or significant GPU hours if self-hosted.
If I need to actually put this into production -I would use a shadow index strategy. You spin up the new index in parallel while the old one keeps serving traffic. You run both retrievers simultaneously during a transition window, compare retrieval quality against a held-out eval set, and cut over once you’ve verified the new index is actually better.
Interviewer: Ok, sounds good. Lets keep going.
Query Understanding
Candidate: Alright, that’s the offline side. Now let me switch to what happens in real time when a user submits a question.
The first thing that happens isn’t retrieval. It’s query understanding. The raw query a user types is often not the best form for retrieval. Users write conversationally. They ask things like “what happens if I miss the open enrollment deadline?” which is verbose and colloquial. Embedding that directly into the same space as dense technical document chunks creates a domain mismatch.
So I’d run the query through a lightweight LLM (a small, fast model, not the expensive generation model) to rewrite it into one or more search-friendly forms. That question might become “open enrollment deadline policy” and “consequences of missing open enrollment.” For longer multi-part questions, this might produce three or four sub-queries that get retrieved in parallel and merged.
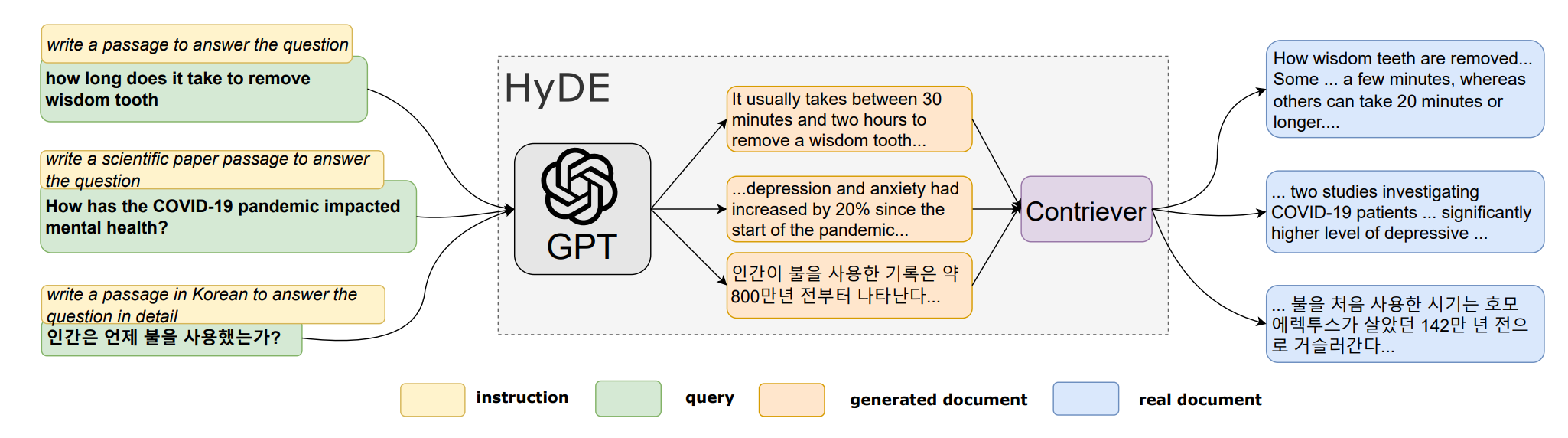
There’s also a more aggressive variant of this called HyDE (Hypothetical Document Embedding), where instead of embedding the query, you generate a short hypothetical document that would answer the question and embed that. The intuition is that a hypothetical answer lives closer in embedding space to real document passages than the question itself does. It works surprisingly well for complex or abstract questions.
Beyond query rewriting, I’d also extract any metadata filters from the question. “What did legal publish last month?” should translate to department equals Legal and a date filter for the last 30 days. And in a multi-turn conversation, I’d prepend a brief summary of the last two or three turns to provide context. Otherwise, follow-up queries like “what about part-time employees?” become ambiguous.
Interviewer: How do you handle a query about something the corpus just doesn’t cover? Query rewriting and HyDE would still run, and you just get bad retrieval results silently.
Candidate: Right, and that’s exactly where the confidence gate matters, which I’ll get to. But at the query understanding stage there’s actually one proactive thing you can do: query intent classification. A lightweight classifier can flag queries that are clearly out of scope before retrieval even runs: off-topic questions, queries about external companies, queries that match known unsupported categories. Those get a clean “not in scope” response immediately. That’s better for the user and it saves compute. For in-scope queries where retrieval just happens to fail because the corpus has a gap, that’s caught downstream by the confidence gate.
Interviewer: Ok, then lets keep moving
Retrieval - Candidate Generation and Re-Ranking
Candidate: Ok so now we actually get to retrieval. I run this in two stages: candidate generation and re-ranking.
For candidate generation, dense and sparse retrieval run in parallel. I embed the rewritten query, hit the ANN index, get back the top 50 dense candidates. At the same time I run BM25 and get back another top 50 sparse candidates. These two lists get merged using Reciprocal Rank Fusion, or RRF, which combines the rankings using only rank positions rather than raw scores. This is important because cosine similarity and BM25 relevance are on completely different scales, so you can’t directly compare them. RRF sidesteps that entirely. The output is a single fused list of roughly 50 to 80 unique candidates.
Those candidates then go through a cross-encoder re-ranker. Here’s the key distinction. The bi-encoder used during embedding encodes the query and each document independently and computes similarity in the resulting vector space. A cross-encoder takes the query and a candidate document together as a joint input and directly predicts a relevance score. That joint encoding lets the model do fine-grained token-level attention between the query and the document, which is a much more accurate relevance signal. The tradeoff is that it’s much slower, which is why you only run it on the shortlist rather than the full corpus. Something like MiniLM can score 80 candidates in about 300ms. We take the top 5 to 10 from that and pass them to context assembly.
Interviewer: Why RRF instead of a learned fusion model that actually weighs the dense and sparse signals?
Candidate: A learned fusion model requires labeled training data, and it needs to be retrained whenever the query distribution shifts. RRF requires no training at all, no calibration, and it empirically matches or outperforms learned fusion in most benchmarks at this stage. The reason is that at this point in the pipeline, you’re still in a recall-oriented mode. You just need a clean, deduplicated candidate pool. The re-ranker right after it is doing all the precision work. Adding a learned fusion model here is added operational complexity for marginal benefit.
Interviewer: You said the re-ranker takes 300ms. What if the latency budget shrinks?
Candidate: There are a few levers. First, reduce the candidate pool. Scoring 30 candidates is roughly half the latency of 80. Second, use a smaller re-ranker model, there are distilled cross-encoders even smaller than MiniLM. Third, and this is the most practical one for an enterprise use case, cache re-ranking results for popular queries. In an enterprise setting a lot of employees ask the same questions, things like “what’s the parental leave policy?” or “how do I submit expenses?”, and you can cache the full retrieval result at a query embedding cluster level rather than the exact string level, and a significant fraction of traffic hits the cache with zero latency cost.
Interviewer: What if the top-ranked chunk was re-indexed two weeks ago and the source document was updated yesterday?
Candidate: That’s a freshness problem and it’s important to handle explicitly rather than quietly serving stale content. At index time, every chunk stores its indexed timestamp alongside the source document’s last-modified timestamp. At serving time, when the top results are assembled, the serving layer checks those two timestamps against each other. If there’s a mismatch, meaning the source changed after the chunk was indexed, I’d surface a notice to the user: “This document was recently updated. Please verify against the source.” For most documents in a weekly-batch system, a seven-day staleness window is probably acceptable. But for time-critical documents, like a policy that changes the moment legal approves it, I’d add a priority re-indexing queue that processes those specific documents within minutes of an update, outside the weekly batch.
Interviewer: Ok, sounds reasonable. Lets continue
 : The Next Chapter in GenAI | by Ramakrishna Sanikommu | Medium")
Context Assembly
Candidate: Alright, so we have the top 5 to 10 chunks from re-ranking. Now I need to assemble them into a prompt that gives the LLM the best chance of producing an accurate, grounded answer.
I do two things to the chunks before sending them to the model. First, context expansion. For each chunk I also pull its neighboring chunks from the same document, the ones immediately before and after it. A chunk that ends mid-argument gives the LLM incomplete information, and the hierarchical structure I set up at indexing time makes this a cheap lookup by chunk position.
Second, context compression. If the assembled context is getting long, I run a lightweight extractive model that scores each sentence in each chunk for relevance to the specific query and keeps only the highest-scoring sentences. This removes noise and actually reduces hallucination, because the LLM is less likely to latch onto tangential context if it isn’t there.
The final prompt has three parts. A system prompt that explicitly constrains the model: “Answer only from the provided context. If the answer isn’t there, say so. Do not speculate or draw on general knowledge.” The retrieved chunks, each labeled with the source document name, section, and last-modified date. And then the user’s original question.
I’d stream the response rather than waiting for the full completion. That gets the first tokens to the user at around 1.5 to 2 seconds and dramatically improves how fast the system feels even if total time is close to 5 seconds.
Interviewer: What if two of the retrieved chunks contradict each other? Say one policy document from March says employees get 15 days, and the updated one from last week says 12. The LLM will try to synthesize those silently.
Candidate: Yeah, that’s a real scenario and the worst thing that can happen is the LLM averaging them out and confidently saying 13 days. The right behavior is to surface the conflict, not silently resolve it. I’d handle it at two levels. At context assembly time, if two chunks come from documents with the same title and department but different last-modified timestamps, the assembly layer flags that as a version conflict and inserts a structured notice: “Note: two versions of this document exist. The content below is from the most recent version, dated X.” Then in the generation prompt itself, I’d explicitly instruct the model: “If the provided context contains contradictory information, state the contradiction and cite both sources rather than choosing one.” The user sees the conflict explicitly and knows to go verify with the authoritative source.
Interviewer: Sounds reasoable, let move to what else you could do?
Garudrails
Candidate: Ok, now guardrails. This is where a lot of production RAG systems fail silently, so I want to be specific about what defense in depth actually looks like here.
The first and most important layer is a retrieval confidence gate. Before the LLM is even called, I check the top re-ranker score against a minimum threshold. If the highest-relevance chunk doesn’t clear that threshold, the system returns a clean “I couldn’t find a reliable answer to this in the available documents” and stops there. This is critical. The majority of RAG hallucinations don’t happen because the LLM is making things up unprompted. They happen because the retrieval failed and the LLM was handed an empty or loosely relevant context and asked to fill in the gap from parametric memory. Stopping that at the source is more effective than any amount of prompt engineering.
The second layer is citation enforcement in the generation prompt. The model is required to cite a specific source chunk for every factual claim it makes. This forces it to stay anchored to retrieved content. If it can’t point to a source, it shouldn’t be saying it.
![Literature Review] Citation Failure: Definition, Analysis and Efficient Mitigation](https://substackcdn.com/image/fetch/$s_!bOBD!,w_1456,c_limit,f_webp,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F95cdb1cd-5c40-4c88-b6a0-2fe8c5744252_825x683.bin "Literature Review] Citation Failure: Definition, Analysis and Efficient Mitigation")
The third layer is post-generation faithfulness scoring. After the model produces a response, I run a lightweight NLI model that checks whether each sentence in the response is actually entailed by the retrieved context. Sentences that aren’t entailed get flagged, and if the overall faithfulness score drops below a threshold the system either regenerates with a stricter prompt or returns a partial answer with a disclaimer.
And finally, answer confidence tiers in the UI. High confidence answers go out with full citations. Medium confidence ones go out with a “please verify with the source document” note and a direct link. Low confidence ones just say “I don’t have a reliable answer to this” and offer an escalation path to a human expert.
Interviewer: The faithfulness scoring step runs after generation, so it adds latency. How do you keep end-to-end under 5 seconds?
Candidate: The trick is running faithfulness scoring in parallel with response streaming, not sequentially after it. The moment generation starts, the response is streamed to the user. Faithfulness scoring runs on each completed sentence as the stream progresses. It’s checking sentence one while the LLM is generating sentence two. By the time the user has read the first few sentences, the faithfulness check on those sentences is already done. If a violation is detected mid-response, the UI inserts a warning banner rather than interrupting the stream. The NLI model itself is small. A distilled DeBERTa variant can score a sentence in under 50ms, and the full pass on a typical response completes well inside the streaming window. The user perceives no added latency at all.
Interviewer: What about access control? Your retrieval layer doesn’t know what documents a given user is allowed to see.
Candidate: Access control needs to be enforced as a hard pre-retrieval filter, not a post-retrieval cleanup. At index time, every chunk is tagged with the access tier of its source document, whether that’s public, team-restricted, or executive-only. At serving time, the user’s authenticated identity is looked up and their permission set is resolved before any retrieval query runs. The ANN and BM25 queries are both scoped to only chunks in the user’s allowed access tiers. Nothing confidential ever enters the candidate pool for an unauthorized user. It’s enforced server-side, not client-side, so it can’t be bypassed. One nuance worth calling out: some enterprise documents have public preambles but restricted appendices. Document-level access tagging isn’t granular enough for those. You need chunk-level access tags that can reflect section-level permissions within the same file.
Part 3: Evaluation
Interivewer: Ok, how about evals?
Candidate: I’d structure evaluation across five layers, each targeting a different stage of the pipeline.
The first is ingestion and chunking quality. This is the most neglected layer and the most upstream source of downstream failures. If chunks are broken, nothing else can fix it. I’d run three checks: a boundary sensitivity test to verify answer spans aren’t being split across chunk boundaries, a coherence audit sampling chunks to check whether they’re semantically self-contained, and a table fidelity check for documents with known tables. These are offline audits, not live metrics, but they’re non-negotiable before any launch.
The second layer is retrieval quality. Recall@K measures what fraction of relevant documents appear in the top K. MRR measures how high the first relevant result ranks, and NDCG@10 as a graded ranking quality metric. I’d measure these separately for dense-only, sparse-only, and hybrid-plus-RRF, so you can quantify exactly what each component contributes.
Third is re-ranking quality, specifically NDCG@5 before versus after re-ranking to confirm the cross-encoder is actually improving things over the bi-encoder output. I’d also plot a latency-quality tradeoff curve across different re-ranker sizes to find the right operating point.
Fourth is generation quality and grounding. Primary metric is faithfulness, meaning what fraction of generated claims are supported by retrieved context. Secondary metrics are answer completeness scored by an LLM judge, hallucination rate defined as any response containing at least one unsupported claim, and citation accuracy.
And fifth, end-to-end user success. Task completion rate via thumbs up/down feedback, no-answer rate, follow-up query rate as a proxy for whether the previous answer fully resolved the question, and escalation rate to human experts.
 Systems - GeeksforGeeks")
All of this sits on top of a golden evaluation set of 500 to 1000 question-answer pairs, hand-verified by subject matter experts, refreshed quarterly.
Interviewer: Building 1000 labeled pairs sounds expensive. How do you actually bootstrap that?
Candidate: Three approaches that work in practice. First, mine real user queries from a pilot rollout or existing search logs. Real questions are worth far more than synthetic ones because they reflect what employees actually need. Second, LLM-assisted annotation: given a document chunk, have an LLM generate plausible questions whose answers are in that chunk, then have a human curate a sample. That gets you to 1000 pairs at maybe 10x the speed of writing them from scratch. Third, accumulate implicit feedback from production as weak labels: thumbs up/down signals, follow-up queries, escalations. Noisy, but scalable, and it keeps the eval set growing passively over time.
Interviewer: You track no-answer rate as a metric. How do you tell the difference between a corpus gap and retrieval being broken? They produce the same number.
Candidate: That’s exactly right, which is why you can’t diagnose it from the no-answer rate alone. You need the retrieval quality metrics running in parallel. If no-answer rate spikes but Recall@K on the eval set stays stable, that’s a corpus gap. Users are asking about something that genuinely isn’t documented yet. If both degrade together, that’s a retrieval regression, probably caused by a corpus update or a chunking change that broke the index. I’d add one more signal: query clustering on the unanswered queries. If the unanswered cluster maps to a coherent topic that isn’t in the corpus, it’s a documentation gap to escalate to the content team. If it’s spread across topics that previously had good coverage, it’s a technical regression to investigate in the indexing pipeline.
Interviewer: Ok, what else in evals?
Online Monitoring
Candidate: Ok, last piece. Once this system is live, how do you make sure it doesn’t slowly degrade without anyone noticing?
I’d monitor three things continuously. First, query drift. The distribution of what users are asking will shift over time as the company changes. I’d track the embedding distribution of incoming queries using a rolling similarity metric against the previous 30-day window. A drift spike usually means users are asking about topics the corpus doesn’t yet cover well, which is a content gap signal, not an ML failure.
Second, per-query quality signals. The faithfulness scorer runs in production on every response, so I’d aggregate rolling faithfulness rate, rolling no-answer rate, and P95 end-to-end latency broken down by pipeline stage. That last part is important. If P95 degrades, you want to know immediately whether it’s retrieval, re-ranking, or generation that’s the bottleneck.
Third, corpus health probes. For the top 100 most queried documents, I’d maintain a set of known question-answer pairs tied to each one. After every weekly batch update, run those probes and alert if Recall@K drops. That catches cases where a document update silently broke retrieval for a high-traffic topic.
All of these feed into a continuous improvement loop. Retrieval feedback from user signals gets used to periodically fine-tune the embedding model and re-ranker on in-domain data. Query categories with low satisfaction get targeted with prompt experiments. And topic clusters with high no-answer rates get surfaced to the content team as documentation gaps.
Interviewer: Fine-tuning on user feedback sounds good in theory, but users only give feedback on answers they actually received. Your training signal is biased toward the cases where retrieval already worked.
Candidate: Yes, that’s the exposure bias problem. You only collect labels for what you surfaced, so your fine-tuning data systematically underrepresents retrieval failures. Two ways to address it. First, hard negative mining: for each positively-labeled query-document pair, sample documents that ranked highly but weren’t selected as relevant. These serve as contrastive negatives in the fine-tuning objective and teach the model what not to retrieve. Second, randomized exploration: periodically inject a small fraction of deliberately randomized retrieval results, surfacing documents the model wouldn’t ordinarily rank highly, and collect feedback on those. This generates labeled examples from outside the current retrieval distribution. The randomized results are flagged internally and never shown as authoritative answers, only used to build training signal. It’s the same principle as epsilon-greedy exploration in bandit systems.
Interviewer: That’s thorough. I think that covers everything I had. Any questions for me?
Candidate: Actually yes. In practice, what does the feedback loop look like between the RAG team and the people who actually write the documents? In my experience the hardest part of shipping one of these systems isn’t the ML. It’s getting document authors to structure their content in ways that make retrieval reliable. Are you seeing teams solve that through tooling, training, or governance?
Sidebar: Asking a question that identifies the organizational friction behind the technical system signals production experience. The best RAG systems aren’t bottlenecked by retrieval algorithms. They’re bottlenecked by document quality. Asking about this shows you’ve actually shipped one of these.
Final Takeaways
This question looks like an ML system design question, but it’s really testing five things at once: your ability to separate offline and online concerns, your depth on the retrieval stack, your awareness of where LLM-based systems fail in production, your ability to evaluate at each stage rather than just end-to-end, and your instinct for how systems degrade over time.
Pay close attention to a few things we emphasize -
Keep offline and online separate from the start. Conflating them leads to designs that are either stale or too slow. The moment you say “I’d think about this as two separate systems,” you’re already signaling architectural maturity.
Go deep on chunking. Most candidates treat it as a footnote. It’s one of the highest-leverage decisions in the entire pipeline. Hierarchical chunking, structural awareness, boundary overlap, and chunk-to-document linking are what make retrieval work reliably rather than intermittently.
Name the dual index explicitly. Dense-only retrieval has a systematic blind spot on exact-match queries. Sparse-only retrieval misses semantic meaning. Hybrid plus RRF is the production standard and naming it specifically shows you’ve worked on real retrieval systems.
Layer the guardrails. Confidence gating, citation enforcement, faithfulness scoring, and confidence tiers in the UI each catch a different failure mode. Treating the system prompt as the full answer to hallucination is a red flag.
Evaluate each stage separately. A strong candidate has a distinct metric for chunking, retrieval, re-ranking, generation, and end-to-end success. Collapsing everything into one user satisfaction metric makes it nearly impossible to diagnose where things went wrong.
Close the monitoring loop. A RAG system at launch is not a finished product. Query drift, corpus updates, and accumulating feedback all create continuous improvement opportunities. Describing this loop explicitly is what separates a production mindset from a prototype mindset.
And that everything!