
Data Science Case Study: Design a Short-Video Recommender System

This post will help you figure out how to approach a Data Science / ML System Design Case Study. The post follows a multi-turn interview conversation. I'll add sidebars so you understand the structure and strategy behind each move.
The Question
Interviewer: Design a short-video recommender system for LinkedIn.

Part 1: Clarifying Questions
Before diving into any design, the goal is to anchor on objectives, constraints, and scale. This signals structured thinking and prevents you from solving the wrong problem.
Candidate: Before jumping into the design, I’d like to ask a few clarifying questions.
First, what is the primary business objective here? Is LinkedIn launching a short-video feed (similar to a “For You” page) to drive engagement and time-on-platform, or is the goal more about professional discovery, such as surfacing relevant career content, thought leadership, and job-adjacent videos?
Interviewer: Great question. Think of it as a dedicated short-video feed on LinkedIn, similar to the LinkedIn Videos tab. The primary goal is short-term engagement (watch time, likes, comments, shares), with a secondary goal of professional relevance, meaning users should feel the content is useful to their careers, not just entertaining.
Candidate: Got it. Quick follow-up on scale: are we designing for LinkedIn at its current scale, which is roughly 1 billion+ registered users and a significant daily active user base? Or a hypothetical greenfield system?
Interviewer: Assume LinkedIn scale. Large, but you can ballpark it. Call it 200 million daily active users.
Candidate: One more: what is our latency SLO? Specifically, what is the target 99th-percentile latency for producing the next batch of video recommendations?
Interviewer: LinkedIn is a near-real-time product. Target under 200ms for producing a fresh recommendation slate.
Sidebar: Three clarifying questions is the sweet spot. You’ve locked in (1) the objective, (2) scale, and (3) latency. Don’t over-clarify, the interviewer wants to see you design, not interrogate. Now summarize your constraints before proceeding.
Candidate: Perfect. To summarize our design constraints:
Platform: LinkedIn short-video feed, ~200M DAU
Primary objective: Maximize engagement (watch time, likes, shares, comments)
Secondary objective: Professional relevance (content should feel career-adjacent)
Latency SLO: 200ms at P99 for a fresh recommendation slate
Signals available: Impressions, watch/dwell time, likes, comments, shares, saves, follows, profile views triggered from a video, and timestamps + device/context for each event
Let me think for a moment before walking through the design.
Sidebar: It’s fine to pause for up to 60–90 seconds to think. Think out loud and narrate your mental model. “I’m thinking about this as a multi-stage problem…” This shows process, which is what the interviewer is evaluating.
Need more questions? Make sure to checkout PracHub
Part 2: High-Level Architecture
Candidate: I’d design this as a multi-stage recommendation pipeline. There are fundamentally two problems here: (1) retrieving a manageable candidate set from a massive video corpus, and (2) ranking those candidates precisely. These have different computational budgets and objectives, so they should be separate stages.
I’ll walk through: Retrieval → Ranking → Re-ranking & Business Rules → Serving. Does that structure work?
Interviewer: Yes, go ahead.
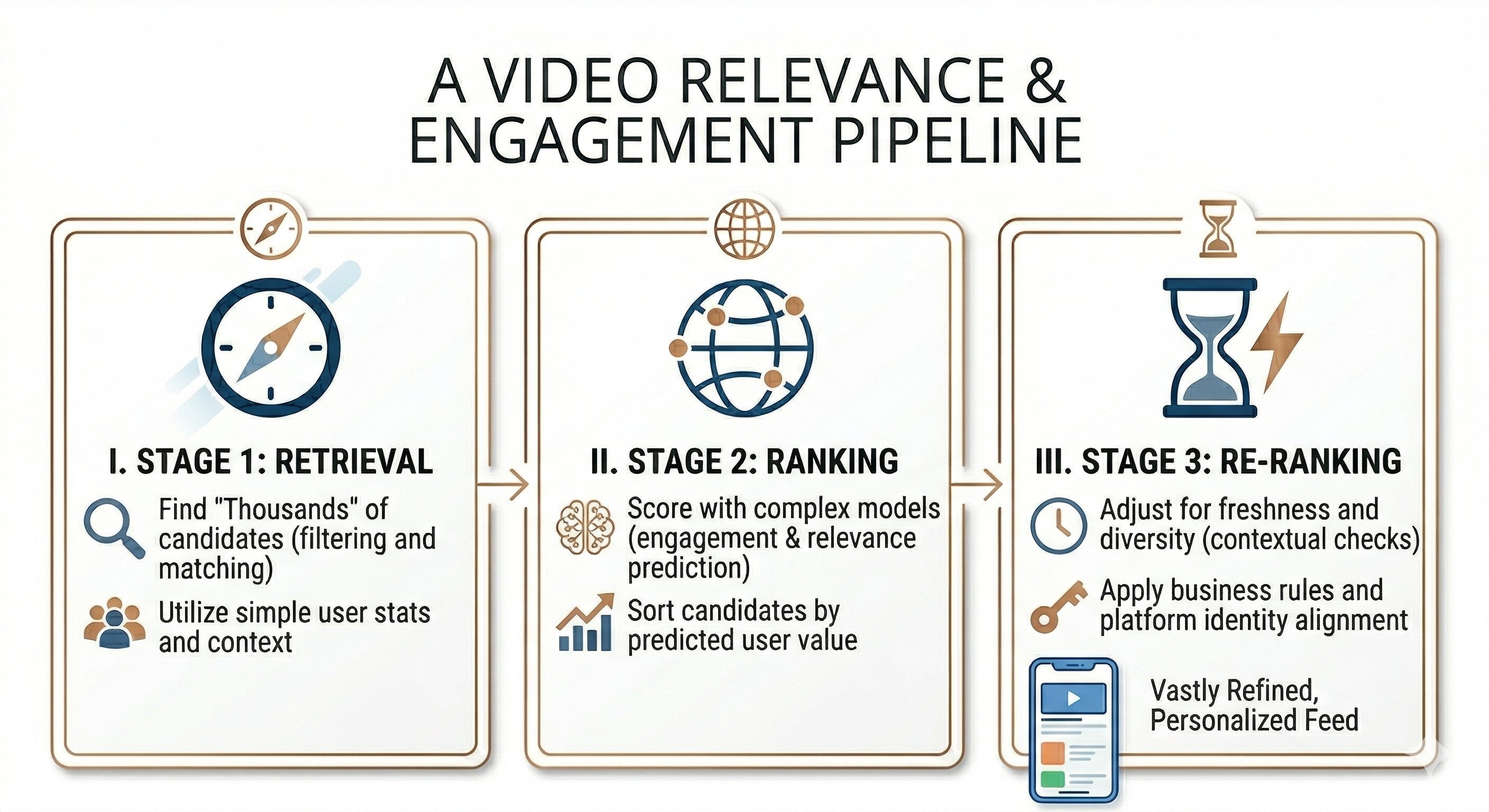
Candidate Generation (Retrieval Layer)
Candidate: The retrieval layer is the first stage. Its job is to narrow down millions of videos to a few hundred candidates, fast. We’re optimizing for recall here, not precision. The ranker will handle precision.
I’d pull candidates from six distinct sources, each targeting a different relevance signal:
Session-based retrieval: A transformer or GRU trained on the user’s recent watch sequence produces a real-time session embedding. We query an approximate nearest neighbor (ANN) index like FAISS or ScaNN to find videos similar to what the user has watched in the last few minutes. This captures short-term intent and typically returns ~200 highly relevant candidates.
Long-term interest retrieval: A dual-encoder model trained with a contrastive objective produces a long-term user embedding in the same latent space as video embeddings. Querying the same ANN index returns candidates aligned with the user’s career topics and content taste built over weeks or months.
Professional graph retrieval: LinkedIn’s professional graph is a first-class signal. We can sample recent videos from connections, followed creators, and companies the user follows. This keeps the feed socially grounded, a distinct advantage LinkedIn has over TikTok or Instagram.
Trending and professionally relevant content: A Redis cache stores the top-velocity videos from the last few hours, sorted by engagement rate, not raw counts (to avoid recency bias). For LinkedIn, we also maintain a “trending by topic” layer (e.g., trending in AI, trending in Finance) so users see what’s gaining traction in their professional domain.
Freshness pool: A separate index of videos uploaded in the last 10–30 minutes. Short-form video momentum is highest in its first hours, surfacing new uploads accelerates creator growth, which is an important platform health metric.
Exploration: A contextual bandit or epsilon-greedy sampler injects content outside the user’s established interest clusters. This prevents the feed from collapsing into a narrow filter bubble and helps the system learn from new signals.
All candidates pass through hard filters (blocked users, duplicate suppression, geographic restrictions) and soft filters (quality heuristics, minimum engagement thresholds for non-fresh content). The result: ~300–400 filtered candidates sent to the ranking layer.
Interviewer: Why do you use an ANN index rather than exact search?
Candidate: Exact k-nearest-neighbor search is O(N) per query and infeasible at millions-of-videos scale within a 200ms budget. ANN algorithms like FAISS or ScaNN achieve sub-linear lookup by building tree- or graph-based indexes that trade a small amount of recall (~1-2% miss rate) for orders-of-magnitude speed improvement. At LinkedIn’s scale, the throughput gain far outweighs the marginal recall loss, especially since the ranking layer will re-score everything anyway.
Interviewer: You mentioned a contextual bandit for exploration. Why put it in retrieval rather than ranking?
Candidate: The retrieval layer decides which candidates even enter the pool. Exploration at this stage has a low cost, the bandit affects which videos are considered, not necessarily which ones are shown. The ranking and re-ranking layers still filter and order the final slate, so we have a safety net. If we only explored at the ranking stage, we’d be constrained to candidates the retrieval layer already surfaced, which could systematically exclude entire content categories. Exploration at retrieval is a structurally safer place to take bets.
Part 3: Ranking Layer
Interviewer: Let’s go deeper on ranking.
Candidate: The ranking layer operates in two tiers: a lightweight first-stage ranker and a heavier second-stage re-ranker.
First-Stage Ranker (Light Ranker)
This model scores all ~300–400 candidates using fast, pre-computed features and filters them down to ~50–100. I’d use a gradient-boosted decision tree (GBDT) - XGBoost or LightGBM, because they run on CPU, have sub-millisecond inference latency, and routinely outperform shallow neural networks on tabular features.
Features used at this stage:
Creator-level engagement rate (aggregated, cached)
Video recency
Historical click-through rate on similar content for this user
Topic match score between video tags and the user’s professional topics
User session activity score (are they in a deep scroll, or just opened the app?)
Second-Stage Re-ranker (Heavy Ranker)
This is where the precision work happens. I’d use a multi-task transformer model that jointly predicts several engagement outcomes simultaneously: probability of a long watch (>80% completion), like probability, comment probability, share probability, and profile click probability (specific to LinkedIn i.e. a proxy for professional relevance).
Interviewer: Why multi-task? Why not one model per outcome?
Candidate: Three reasons. First, data efficiency - rare actions like shares or profile clicks have sparse training signal. Co-training with abundant signals (watch time) helps the model generalize to rare outcomes. Second, representation quality - shared layers learn that “a user who watches finance content to completion tends to also follow finance creators” - that correlation improves all predictions simultaneously. Third, it’s operationally simpler - one model to train, monitor, and serve instead of five.
The multi-task model outputs one probability per engagement type. These are then combined into a utility score using a weighted sum across the predicted outcomes. Concretely, you assign a weight to each action type based on how much it reflects your objective, and the final score for a video is the sum of each predicted probability multiplied by its corresponding weight. Since our primary objective is engagement and the secondary objective is professional relevance, long watch probability gets the highest weight in this sum, and profile click probability (the professional relevance signal) gets a meaningful but smaller weight to ensure relevant career content consistently surfaces.
The key design decision is in how you set those weights. In practice, they are tuned via offline experiments on historical engagement data and validated in A/B tests to confirm they produce the desired balance between entertainment and professional value.
Interviewer: You mentioned the secondary objective is professional relevance. How do you enforce that without hurting engagement?
Candidate: This is the tension at the heart of LinkedIn’s short-video product. A pure engagement optimizer will converge on viral entertainment. There are two levers to address this.
Feature engineering: Add a “professional relevance score” to the ranker features- this could be a cosine similarity between the video’s topic embedding and the user’s inferred professional domain. The ranker learns its effect on downstream utility.
Constrained re-ranking: At the re-ranking stage, enforce a soft constraint: e.g., at least 30% of the final slate must have a professional relevance score above a threshold. This is implemented as a greedy constrained optimization that maximizes total utility subject to the diversity constraint. It adds milliseconds, not seconds.
Part 4: Re-Ranking and Business Rules
Interviewer: How do you handle business rules, for example, promoting new creators, or suppressing low-quality content?
Candidate: Business rules sit in a post-ranking adjustment layer and operate after the heavy ranker assigns utility scores. I see three main mechanisms here.
Score-based reweighting: Multiply the utility score by a small boost factor (e.g., 1.1x) for new creators who have fewer than 1,000 followers and a positive early engagement signal. This levels the playing field without overriding the model entirely.
Quota-based constraints: Enforce minimums and maximums, for example, no more than two videos per creator in the top 20 slots, or at least 10% of the slate from creators the user doesn’t already follow (discovery quota). These can be solved efficiently with a greedy constrained re-ranking algorithm.
Hard filters: Safety classifiers (hate speech, misinformation detectors) run in parallel and remove flagged content before any score is applied. These are non-negotiable and run at retrieval time, not ranking time, to avoid wasting compute.
Part 5: Handling the Cold Start Problem
Interviewer: What do you do about new users and new videos with no engagement history?
Candidate: The cold start problem has two sides: item cold start (new videos) and user cold start (new users). Let me walk through each.
For new videos: When a video is uploaded, we extract multimodal features immediately, thumbnail via computer vision, audio features, transcript text embeddings, and metadata tags. These are used for content-based retrieval before we have behavioral signals. We then implement a controlled exploration strategy: new videos are shown to a small, diverse sample of users whose historical profiles suggest broad interests. This generates initial engagement signals within hours, at which point the behavioral features catch up.
For new users: LinkedIn has a significant advantage here. Users provide rich professional signals during signup, including job title, industry, skills, and education. We can use these to map new users into professional topic clusters and bootstrap recommendations from high-performing content in those clusters. As the user engages, we gradually shift weight from the cluster-based features to personalized behavioral features.
Interviewer: What’s the transition mechanism? How do you know when a user has “enough” history?
Candidate: I would use a confidence-weighted blend: the recommendation score is a linear interpolation between the cluster-based collaborative score and the personalized model score, where the interpolation weight is a function of the number of significant interactions (for example, videos watched longer than 10 seconds). Below 10 interactions, we lean heavily on cluster-based signals. Above 50, the personalized model takes over nearly entirely. The threshold is a hyperparameter tuned via offline evaluation.
Part 6: Measurement and Experimentation
Interviewer: How would you measure the impact of this system?
Candidate: I’d structure measurement around three tiers:
Primary engagement metrics:
Average watch time per session
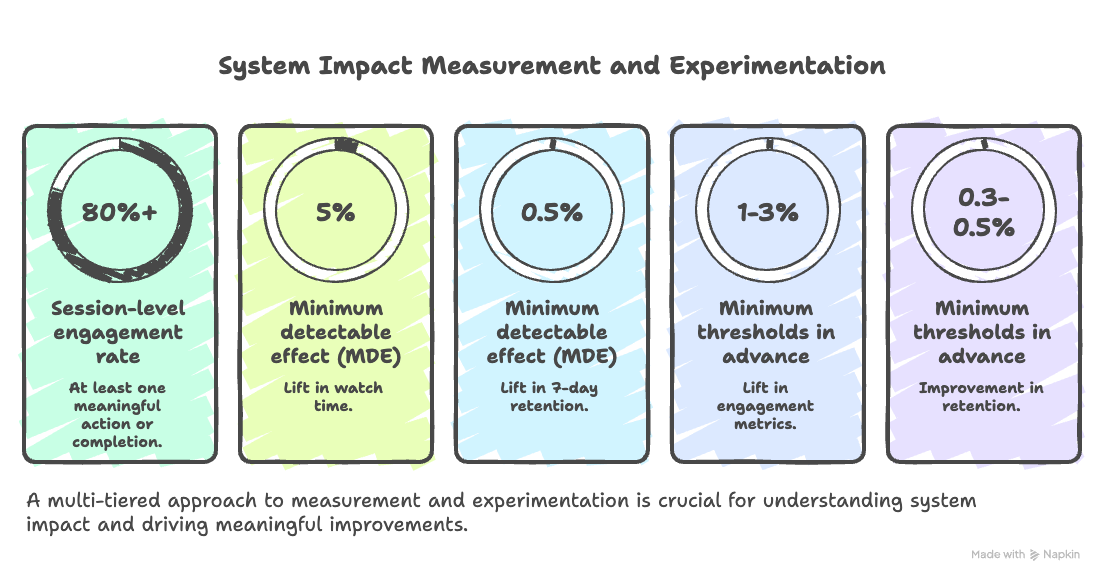
Session-level engagement rate (at least one meaningful action: like, comment, share, or 80%+ completion)
Return session rate (7-day and 28-day)
Professional relevance guardrails:
Profile clicks triggered from a video (proxy for professional value)
Creator follower growth rate (platform health)
Content diversity index per user (prevents filter bubble collapse)
System health metrics:
P99 recommendation latency
Model inference throughput
Cache hit rates for candidate generators
For experimentation, I’d run an A/B test with randomized user assignment. The control group sees the current feed (or a popularity-based baseline if this is a new product), and the treatment group sees the new recommender.
Interviewer: How do you decide how long to run the test and what effect size is meaningful?
Candidate: Two factors determine test length: statistical requirements and behavioral stabilization. Let me break those down.
Statistically, the minimum run time is a function of:
Baseline metric rate - e.g., if average watch time per session is 3 minutes, we set that as our baseline.
Minimum detectable effect (MDE) - for LinkedIn, a 5% lift in watch time or a 0.5 percentage point lift in 7-day retention would both be meaningful, given the compounding effect at 200M DAU scale.
Traffic volume - with 200M DAU and a 50/50 split, we reach sample sizes for most metrics within 1–2 days, but we should always run at least one full week to account for weekday/weekend behavioral differences and to smooth novelty effects.
For business significance, I’d define minimum thresholds in advance: a 1–3% lift in engagement metrics is meaningful at scale; for retention, even a 0.3–0.5 percentage point improvement compresses to significant revenue and creator ecosystem impact over time.
Sidebar: Explicitly addressing novelty effects (where users engage more simply because the content is new/different) is a signal of production experience. Interviewers at L5+ levels will probe for this.
Part 7: Position Bias
Interviewer: One more deep-dive question - LinkedIn’s video feed is an infinite scroll. How do you handle position bias in training data?
Candidate: This is a subtle but important problem. In a standard ranked list, items shown at the top receive more clicks because they’re at the top, not necessarily because users prefer them. This creates biased training data, where the model learns to reinforce whatever the current system surfaced.
For infinite scroll short-video feeds, position bias has a different character than standard search result bias. Users do not leave after one click and instead scroll continuously. A video at position 3 versus position 8 has meaningfully different exposure probability even if the user scrolls to position 8.
I’d address this with propensity-weighted training:
Estimate exposure probabilities using a position bias model. This model estimates the probability that a video at position k was actually seen by a user who scrolled to that depth. For short-video feeds, this is a survival-style model conditioned on the user’s scroll depth in the session.
Apply inverse propensity scoring (IPS) to upweight engagement signals from lower-ranked items (they were seen despite lower exposure) and downweight signals from top-ranked items (higher exposure inflates apparent preference).
Separately train a propensity model on counterfactual data by occasionally randomizing a fraction of impressions to break the feedback loop and generate unbiased exposure samples.
Interviewer: That’s very thorough. I think that covers what I had. Any questions for me?

Candidate: Yes - for LinkedIn’s video team specifically, how are you currently balancing the tension between professional relevance and raw engagement optimization? And is there a dedicated creator-side team working on distribution fairness, or is that handled within the recommendation team?
Sidebar: Asking smart, specific questions at the end signals genuine interest and domain knowledge. Avoid asking questions you could easily Google. Questions about team structure and unsolved tensions show you have internalized the design deeply.
Final Takeaways
This question looks like a system design question on the surface, but it is really testing five things at once: your ability to clarify before building, your understanding of multi-stage ML pipelines, your intuition about trade-offs, your awareness of production realities, and your domain knowledge of the specific platform.
Here are the moves that separate a strong answer from an average one:
Clarify the objective before drawing anything. The answer to “design a short-video recommender” is completely different depending on whether the goal is raw engagement or professional relevance. Locking this in early keeps the entire design coherent.
Frame retrieval and ranking as separate problems. Retrieval is a recall problem with a tight latency budget. Ranking is a precision problem with a richer feature set. Conflating the two leads to systems that are either too slow or too imprecise.
Use LinkedIn’s unique signals. The professional graph, profile data at signup, and professional topic clusters are real advantages LinkedIn has over TikTok or Instagram. A generic recommender design that ignores these signals will feel shallow to the interviewer.
Anticipate the hard questions. Position bias in infinite scroll, cold start for both users and items, and the tension between engagement optimization and content quality are all areas the interviewer is likely to probe. Walking into these proactively, rather than waiting to be asked, signals production experience.
Connect measurement back to the objective. Every metric you track should tie back to either the primary goal (engagement), the secondary goal (professional relevance), or a guardrail (platform health, creator fairness). Listing metrics without explaining why they matter is a missed opportunity.