
Building a Tiny Transformer From Scratch in PyTorch
(and understanding every piece along the way)

If you’ve ever felt that Transformers are a “black box,” today’s post is for you. Instead of just downloading a pretrained model, we’re going to build a tiny GPT-style transformer from scratch — small enough to run on your laptop, but powerful enough to generate Shakespeare-like text.
By the end, you’ll not only have a working model, but also a clear understanding of how the pieces fit together: embeddings, attention, feedforward networks, and residual connections.
But first, if you are new to Transformer, check out this blog to get the concepts down before you start coding.
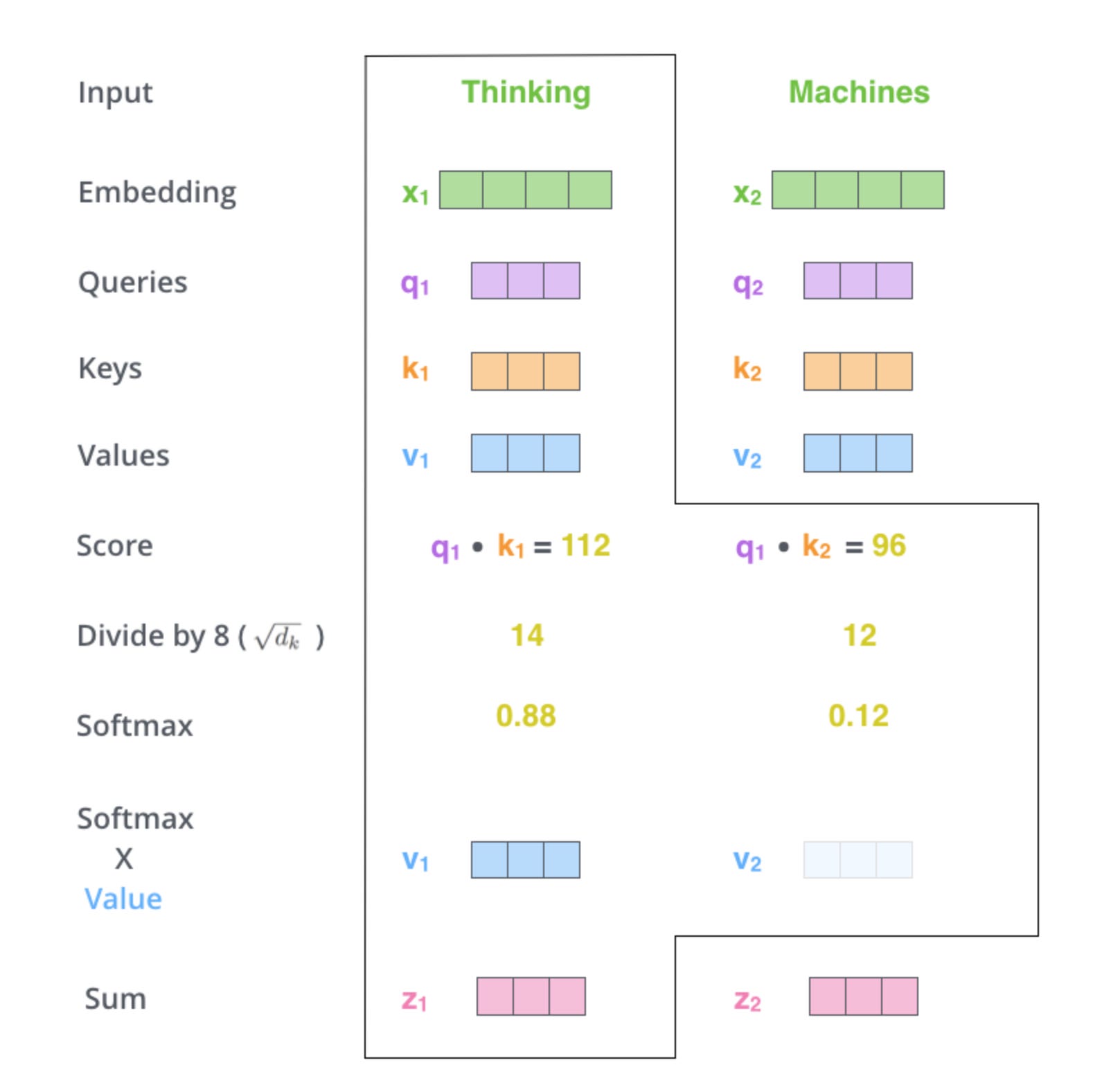
Fig 1. Query, Key, Value vectors used in attention. Src: Illustrated Transformer
1. The Setup: Hyperparameters & Data
Transformers need a few key hyperparameters: embedding size, number of layers, number of heads, context window size, etc. We’ll keep everything small for speed.
device = ‘cuda’ if torch.cuda.is_available() else ‘cpu’
block_size = 128 # how many characters the model looks back
batch_size = 32 # sequences per batch
n_layer = 2 # number of transformer blocks
n_head = 2 # attention heads
n_embd = 128 # embedding size
dropout = 0.1
max_iters = 1200 # training steps
lr = 3e-3
We’ll use a small excerpt of Shakespeare for training. Since it’s tiny, we’ll tokenize at the character level — every character (including spaces and punctuation) is a token.
text = “”“From fairest creatures we desire increase,
That thereby beauty’s rose might never die,
...”“”
chars = sorted(list(set(text)))
vocab_size = len(chars)
stoi = {ch:i for i,ch in enumerate(chars)}
itos = {i:ch for ch,i in stoi.items()}
encode = lambda s: torch.tensor([stoi[c] for c in s], dtype=torch.long)
decode = lambda t: ‘’.join(itos[int(i)] for i in t)
Why characters instead of words? Simplicity.
Note: Character-level model predicts letters, not words/subwords. It can learn “Thy ” but has no concept of words, so you get non-words and odd spellings.
2. Attention: The Heart of the Transformer
If embeddings are how we represent words or characters, then attention is how the model decides what to focus on.
Think about reading Shakespeare:
“From fairest creatures we desire increase…”
To predict “increase,” you might need to remember “desire” a few tokens back. Attention gives the model this ability: each token can “look” at others in the sequence and decide how much weight to assign them.
Queries, Keys, and Values
In Transformers, each token embedding is transformed into three vectors:
Query (Q): What am I looking for?
Key (K): What do I contain?
Value (V): What information do I provide if selected?
The model compares Queries and Keys using a dot product. If a Query matches a Key strongly, the corresponding Value is attended to more.
Scaled Dot-Product Attention
Mathematically:
Attention(Q,K,V) = softmax (QK^T /sqrt{d(k)} )V
Q(K^T): Similarity between queries and keys.
Division by sqrt{d(k)}: Prevents overly large values that destabilize training.
Softmax: Turns similarities into probabilities.
Multiply by V: Aggregate information from the sequence.
Causal Masking
In language modeling, we only want each token to see past tokens, not future ones. Otherwise, predicting the next word would be cheating.
That’s why we apply a causal mask: a triangular matrix that blocks access to future positions.
class CausalSelfAttention(nn.Module):
def __init__(self, n_embd, n_head, dropout):
super().__init__()
self.n_head = n_head
self.key = nn.Linear(n_embd, n_embd, bias=False)
self.query = nn.Linear(n_embd, n_embd, bias=False)
self.value = nn.Linear(n_embd, n_embd, bias=False)
self.proj = nn.Linear(n_embd, n_embd, bias=False)
self.attn_drop = nn.Dropout(dropout)
self.resid_drop = nn.Dropout(dropout)
# causal mask: prevents looking ahead
self.register_buffer(’mask’, torch.tril(torch.ones(block_size, block_size))
.view(1,1,block_size,block_size))
def forward(self, x):
B, T, C = x.size()
k = self.key(x).view(B, T, self.n_head, C//self.n_head).transpose(1,2)
q = self.query(x).view(B, T, self.n_head, C//self.n_head).transpose(1,2)
v = self.value(x).view(B, T, self.n_head, C//self.n_head).transpose(1,2)
att = (q @ k.transpose(-2, -1)) / math.sqrt(k.size(-1))
att = att.masked_fill(self.mask[:,:,:T,:T]==0, float(’-inf’))
att = F.softmax(att, dim=-1)
att = self.attn_drop(att)
y = att @ v
y = y.transpose(1,2).contiguous().view(B, T, C)
return self.resid_drop(self.proj(y))
3. Transformer Blocks: The Lego Bricks of LLMs
If attention is the engine, then a Transformer Block is the car around it — a self-contained unit that stacks with others to build deep models. Every modern LLM is basically “just” dozens (or hundreds) of these blocks piled on top of each other.
A Transformer Block has three key ingredients:
Layer Normalization (stabilizes training)
Multi-Head Self-Attention (captures dependencies between tokens)
Feedforward Network (MLP) (adds nonlinear mixing and depth)
And critically: Residual Connections — the skip-connections that let the signal flow across layers without vanishing.
Anatomy of a Block
Mathematically, a block looks like this:
x=x+Attention(LayerNorm(x))
x=x+MLP(LayerNorm(x))
LayerNorm before each sub-layer, residual addition after. This pattern is called Pre-Norm (used in GPT, LLaMA, etc.). It helps with stable gradients during deep training.
class MLP(nn.Module):
def __init__(self, n_embd, dropout):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4*n_embd),
nn.GELU(),
nn.Linear(4*n_embd, n_embd),
nn.Dropout(dropout),
)
def forward(self, x): return self.net(x)
class Block(nn.Module):
def __init__(self, n_embd, n_head, dropout):
super().__init__()
self.ln1 = nn.LayerNorm(n_embd)
self.attn = CausalSelfAttention(n_embd, n_head, dropout)
self.ln2 = nn.LayerNorm(n_embd)
self.mlp = MLP(n_embd, dropout)
def forward(self, x):
x = x + self.attn(self.ln1(x)) # residual connection
x = x + self.mlp(self.ln2(x))
return x
Residuals (skip connections) are critical — without them, deep networks would struggle to train.
4. The Tiny Transformer
We’ve covered the ingredients:
Embeddings to represent tokens and positions.
Attention to let tokens “talk” to each other.
MLPs to mix information.
Residual + LayerNorm to stabilize everything.
Now it’s time to assemble a complete GPT-style language model.
Think of it like building a house: we’ve poured the foundation (embeddings), installed the plumbing and wiring (attention), and added rooms (blocks). The Tiny Transformer is the full house, ready to be lived in.
Step 1. Token & Positional Embeddings
Transformers don’t know what words or characters are. They only see numbers. So we use an embedding matrix to map token IDs into dense vectors.
But embeddings alone don’t capture order. Without positions, “dog bites man” and “man bites dog” look the same. That’s why we add positional embeddings.
self.tok_emb = nn.Embedding(vocab_size, n_embd) # token embeddings
self.pos_emb = nn.Embedding(block_size, n_embd) # position embeddings
We then add them together:
tok = self.tok_emb(idx) # token lookup
pos = self.pos_emb(torch.arange(T, device=idx.device)) # position lookup
x = tok + pos # combined representation
This ensures the model knows both what the token is and where it is.
Step 2. Stacking Transformer Blocks
Each block is a self-contained reasoning step: normalize → attend → normalize → feedforward → residual connections.
We stack multiple blocks to deepen the model’s capacity:
self.blocks = nn.Sequential(*[Block(n_embd, n_head, dropout) for _ in range(n_layer)])
This is where scaling happens: GPT-2 has 48 blocks, GPT-3 has 96, LLaMA-65B has 80+. In our case, we keep it tiny (2 blocks) so it runs on a laptop.
Step 3. Output Layer
After passing through blocks, we normalize one last time and project into the vocabulary size to predict the next token.
self.ln_f = nn.LayerNorm(n_embd)
self.head = nn.Linear(n_embd, vocab_size, bias=False)
Notice something subtle:
self.head.weight = self.tok_emb.weight
This is weight tying. It reuses the same matrix for input embeddings and output projection, reducing parameters and often improving performance.
class TinyTransformer(nn.Module):
def __init__(self):
super().__init__()
self.tok_emb = nn.Embedding(vocab_size, n_embd)
self.pos_emb = nn.Embedding(block_size, n_embd)
self.drop = nn.Dropout(dropout)
self.blocks = nn.Sequential(*[Block(n_embd, n_head, dropout) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embd)
self.head = nn.Linear(n_embd, vocab_size, bias=False)
# tie weights: reuse embedding weights in output
self.head.weight = self.tok_emb.weight
def forward(self, idx, targets=None):
B, T = idx.shape
tok = self.tok_emb(idx)
pos = self.pos_emb(torch.arange(T, device=idx.device))
x = self.drop(tok + pos)
x = self.blocks(x)
x = self.ln_f(x)
logits = self.head(x)
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
return logits, loss
@torch.no_grad()
def generate(self, idx, max_new_tokens):
for _ in range(max_new_tokens):
idx_cond = idx[:, -block_size:]
logits, _ = self(idx_cond)
logits = logits[:, -1, :]
probs = F.softmax(logits, dim=-1)
next_id = torch.multinomial(probs, num_samples=1)
idx = torch.cat((idx, next_id), dim=1)
return idx
Notice the positional embeddings: since transformers don’t have recurrence or convolution, we need to tell them where each token is in the sequence.
5. Training & Sampling
Training is straightforward: predict the next token, compute cross-entropy loss, update weights.
model = TinyTransformer().to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
for it in range(max_iters+1):
xb, yb = get_batch(’train’)
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
# Generate text
context = torch.zeros((1,1), dtype=torch.long, device=device)
sample = model.generate(context, max_new_tokens=400)[0].tolist()
print(decode(sample))
After training, the model starts spitting out Shakespearean-style gibberish. Again, it's just to understand the architecture - not to build something that works.
6. The Big Picture
Why does this matter? Because when you understand how to build a toy transformer. You can play around with the parameters in the model to understand -
Why attention is powerful.
How scaling (layers, heads, embedding size) affects capacity.
Why modern LLMs are just giant versions of this code — trained on billions of tokens instead of a few hundred lines of Shakespeare.
Here is the full code for you to try out.
# Tiny Transformer (PyTorch) — Colab-ready
# Goal: Train a very small character-level language model (LM) on Shakespeare text.
# This lets you “see” how attention, embeddings, and transformer blocks work.
import math, torch, torch.nn as nn
from torch.nn import functional as F
# -------------------
# Config (small enough to run on CPU/GPU in minutes)
# -------------------
device = ‘cuda’ if torch.cuda.is_available() else ‘cpu’ # use GPU if available
block_size = 128 # context window size (how many characters model looks back)
batch_size = 32 # number of sequences per batch
n_layer = 2 # number of transformer blocks
n_head = 2 # number of attention heads
n_embd = 128 # embedding dimension
dropout = 0.1
max_iters = 1200 # training steps (short for demo)
eval_interval= 200
lr = 3e-3 # learning rate
eval_iters = 100
generate_tokens = 400 # how many characters to generate after training
torch.manual_seed(1337) # reproducibility
# -------------------
# Tiny dataset (Shakespeare excerpt for demo)
# -------------------
text = “”“
From fairest creatures we desire increase,
That thereby beauty’s rose might never die,
But as the riper should by time decease,
His tender heir might bear his memory:
...
“”“
# -------------------
# Tokenization (character-level for simplicity)
# -------------------
chars = sorted(list(set(text)))
vocab_size = len(chars) # number of unique characters
stoi = {ch:i for i,ch in enumerate(chars)} # char → index
itos = {i:ch for ch,i in stoi.items()} # index → char
encode = lambda s: torch.tensor([stoi[c] for c in s], dtype=torch.long)
decode = lambda t: ‘’.join(itos[int(i)] for i in t)
# Prepare train/validation split
data = encode(text)
n = int(0.9*len(data))
train_data, val_data = data[:n], data[n:]
# Function to sample mini-batches for training
def get_batch(split):
d = train_data if split == ‘train’ else val_data
# ensure we never sample beyond available length
cur_block = min(block_size, max(2, len(d) - 2))
hi = len(d) - cur_block - 1
if hi <= 0:
# fall back to using the whole sequence if extremely short
x = d[:cur_block].unsqueeze(0)
y = d[1:cur_block+1].unsqueeze(0)
return x.to(device), y.to(device)
ix = torch.randint(hi, (batch_size,))
x = torch.stack([d[i:i+cur_block] for i in ix])
y = torch.stack([d[i+1:i+cur_block+1] for i in ix])
return x.to(device), y.to(device)
# -------------------
# Core Transformer Components
# -------------------
class CausalSelfAttention(nn.Module):
“”“
Multi-head self-attention with causal masking
(so model can’t look at future tokens).
“”“
def __init__(self, n_embd, n_head, dropout):
super().__init__()
assert n_embd % n_head == 0
self.n_head = n_head
# projection matrices for Q, K, V
self.key = nn.Linear(n_embd, n_embd, bias=False)
self.query = nn.Linear(n_embd, n_embd, bias=False)
self.value = nn.Linear(n_embd, n_embd, bias=False)
self.proj = nn.Linear(n_embd, n_embd, bias=False)
self.attn_drop = nn.Dropout(dropout)
self.resid_drop = nn.Dropout(dropout)
# causal mask (ensures model only attends to previous tokens)
self.register_buffer(’mask’, torch.tril(torch.ones(block_size, block_size))
.view(1,1,block_size,block_size))
def forward(self, x):
B, T, C = x.size()
# Linear projections → split into heads
k = self.key(x).view(B, T, self.n_head, C//self.n_head).transpose(1,2)
q = self.query(x).view(B, T, self.n_head, C//self.n_head).transpose(1,2)
v = self.value(x).view(B, T, self.n_head, C//self.n_head).transpose(1,2)
# Attention scores (scaled dot product)
att = (q @ k.transpose(-2, -1)) / math.sqrt(k.size(-1))
att = att.masked_fill(self.mask[:,:,:T,:T]==0, float(’-inf’)) # apply causal mask
att = F.softmax(att, dim=-1) # normalize
att = self.attn_drop(att)
# Weighted sum of values
y = att @ v
y = y.transpose(1,2).contiguous().view(B, T, C)
y = self.resid_drop(self.proj(y))
return y
class MLP(nn.Module):
“”“Feed-forward network inside each transformer block.”“”
def __init__(self, n_embd, dropout):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4*n_embd), # expansion
nn.GELU(), # nonlinearity
nn.Linear(4*n_embd, n_embd), # projection back down
nn.Dropout(dropout),
)
def forward(self, x): return self.net(x)
class Block(nn.Module):
“”“A Transformer block = LayerNorm + Attention + MLP with residuals.”“”
def __init__(self, n_embd, n_head, dropout):
super().__init__()
self.ln1 = nn.LayerNorm(n_embd)
self.attn = CausalSelfAttention(n_embd, n_head, dropout)
self.ln2 = nn.LayerNorm(n_embd)
self.mlp = MLP(n_embd, dropout)
def forward(self, x):
x = x + self.attn(self.ln1(x)) # residual connection
x = x + self.mlp(self.ln2(x)) # another residual
return x
class TinyTransformer(nn.Module):
“”“A GPT-style tiny transformer model.”“”
def __init__(self):
super().__init__()
# Token + position embeddings
self.tok_emb = nn.Embedding(vocab_size, n_embd)
self.pos_emb = nn.Embedding(block_size, n_embd)
self.drop = nn.Dropout(dropout)
# Stack of transformer blocks
self.blocks = nn.Sequential(*[Block(n_embd, n_head, dropout) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embd)
# Output projection to vocab size
self.head = nn.Linear(n_embd, vocab_size, bias=False)
# Weight tying: share weights between token embedding and output head
self.head.weight = self.tok_emb.weight
def forward(self, idx, targets=None):
B, T = idx.shape
tok = self.tok_emb(idx) # (B,T,C)
pos = self.pos_emb(torch.arange(T, device=idx.device)) # (T,C)
x = self.drop(tok + pos)
x = self.blocks(x)
x = self.ln_f(x)
logits = self.head(x) # (B,T,V)
# Compute loss if targets given
loss = None
if targets is not None:
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1))
return logits, loss
@torch.no_grad()
def generate(self, idx, max_new_tokens):
“”“Generate text by sampling next token repeatedly.”“”
for _ in range(max_new_tokens):
idx_cond = idx[:, -block_size:] # crop to context window
logits, _ = self(idx_cond)
logits = logits[:, -1, :] # last time step
probs = F.softmax(logits, dim=-1) # convert to probabilities
next_id = torch.multinomial(probs, num_samples=1) # sample token
idx = torch.cat((idx, next_id), dim=1)
return idx
# Initialize model + optimizer
model = TinyTransformer().to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
# -------------------
# Evaluation helper
# -------------------
@torch.no_grad()
def estimate_loss():
model.eval()
out = {}
for split in [’train’,’val’]:
losses = []
for _ in range(eval_iters):
xb, yb = get_batch(split)
_, loss = model(xb, yb)
losses.append(loss.item())
out[split] = sum(losses)/len(losses)
model.train()
return out
# -------------------
# Training loop
# -------------------
for it in range(max_iters+1):
if it % eval_interval == 0:
losses = estimate_loss()
print(f”iter {it:4d} | train loss {losses[’train’]:.3f} | val loss {losses[’val’]:.3f}”)
xb, yb = get_batch(’train’)
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # avoid exploding grads
optimizer.step()
# -------------------
# Sampling: generate text from scratch
# -------------------
context = torch.zeros((1,1), dtype=torch.long, device=device) # start with token 0
sample = model.generate(context, max_new_tokens=generate_tokens)[0].tolist()
print(”\n--- SAMPLE ---\n”)
print(decode(sample))